Data Alignment, Aggregation and Vectorisation (DAAV) BB – Design Document – Prometheus-X Components & Services
- Data Alignment, Aggregation and Vectorisation (DAAV) BB – Design Document
- Technical usage scenarios & Features
- Requirements
- Integrations
- Relevant Standards
- Input / Output Data
- Project interface
- Architecture
- Dynamic Behaviour
- Configuration and deployment settings
- Third Party Components & Licenses
- Implementation Details
- OpenAPI Specification
- Test Specification
- Test Reproduction
- Test
- Validate Requirements and Potential Risks
- Testing Independent Features
- Test Case 0: Backend Health Check
- Test Case 1: Verify API Documentation Access
- Test Case 2: Verify User Authentication
- Test Case 3: Verify Dataset Creation
- Test Case 4: Verify Dataset Content Retrieval
- Test Case 5: Verify Node Connection in Workflow Editor
- Test Case 6: Verify Workflow Creation
- Test Case 7: Verify Workflow Execution
- Manual Usage Scenarios
- Internal Unit Tests
- Test Execution Information
- Partners & roles
- Usage in the dataspace
Data Alignment, Aggregation and Vectorisation (DAAV) BB – Design Document
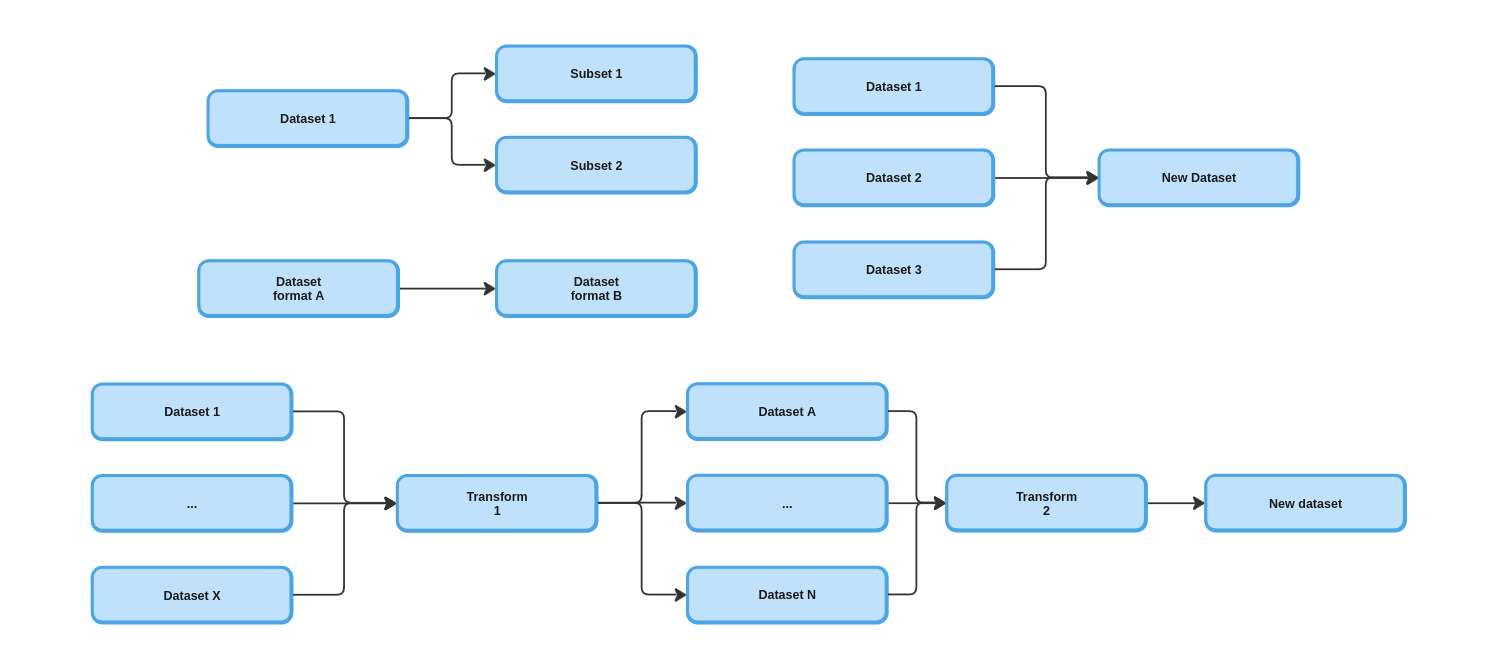
The DAAV building block purpose is to setup data manipulation pipeline to create new dataset by :
- combining data from various source
- filtering them to create subset
- converting them from one format to another
- calculating new data
The project is divided in two modules :
- The front-end offers a user interface to connect various data sources (Prometheus Data Connector, databases, files, API), visualize them and manipulate them (alignment, aggregation and vectorisation). The data manipulation use a visual programming system to create data manipulation pipelines by connecting blocks. Basic roles / organisations / users managment is available.
- The back-end provides API to manage front-end actions, to execute the data manipulation and to expose data.
Blocks are divided in three groups :
- Input block : Each block represent a dataset from Prometheus dataspace or external source.
- Transform block : Can manipulate and transform data.
- Output block : Can store the result and/or expose the new dataset on Prometheus dataspace.
Technical usage scenarios & Features
The first main objective of this building block is to reduce entry barriers for data providers and ai services clients by simplifying the handling of heterogeneous data and conversion to standard or service-specific formats.
The second main objective is to simplify and optimize data management and analysis in complex environments.
Features/main functionalities
Create a connector from any input data model to any output model. Examples :
- xApi custom model to xApi standardized model
- Research datasets (Mnist, commonvoice, etc…) to custom vector
- Custom skills framework to any framework
- Subset of main dataset
Create a aggregator from different data sources :
- link pseudonymised data with identification data for customer followup
- mix data of various subcontractors for global overview
Receive pushed data from PDC.
Tools to describe and explore datasets.
Expert system and AI automatic data alignment.
Technical usage scenarios
- Creation of a new dataset from different sources
- Aggregation of data from multiple sources ensuring data compatibility and standardization.This is useful for data analysts who often work with fragmented datasets.
- Providing mechanism to transform and standardize data formats, such as converting xAPI data to a standardized xAPI format.
- Merging datasets with different competency frameworks to create a unified model.
- Optimize data manipulation and freshness based on user’s needs.
- Give access to specific data based on user rights (contracts and organisation roles)
- Paul is CMO and wants to follow KPIs on each products of his entreprise. He was access to specific data prepared by his IT team
- Arsen is fullstack developper and wants to verify integrity of data generated by his code. He configures his own data to this purpose.
- Christophe is an AI developer and wants to prepare his data for training. He create pipelines with continuous integration.
- Fatim is a data analyst and has been given access to a dataset to calculate specific metrics : mean, quantile, min, max, etc.
- Manage inputs and outputs for others building blocks or AI services.
- Prepare data for Distributed Data Visualization.
- Prepare input and receive (and store) output for Data Veracity and Edge translators.
- Create subsets of a main dataset to test performance of an AI service on each set.
- Front-end : User can retrieve Prometheus-X dataspace ressource or add external ressource and build a transformation workflow from it.
- Back-end : Expose a public endpoint to execute transformation workflow or to get data ; Script-oriented automation ;
- Database : Internal database of the building block to store user ressource location and workflow.
Requirements
BB must communicate with catalog API to retrieve contract.
BB must communicate with pdc to trigger data exchange with pdc.
BB MUST communicate to PDC to get data from contract and consent BB.
BB CAN receive data pushed by PDC.
BB CAN connect to others BB.
BB MUST expose endpoints to communicate with others BB.
BB SHOULD be able to process any type of data as inputs
Expected requests time :
| Type | Requests |
|---|---|
| Simple request | < 100ms |
| Medium request | < 3000ms |
| Large requests | < 10000ms |
Integrations
Direct Integrations with Other BBs
No other building block interacting with this building block requires specific integration.
Relevant Standards
Data Format Standards
JSON - CSV - NoSQL (mongo, elasticsearch) - SQL - xAPI - Parquet - Archive (tar, zip, 7z, rar).
Mapping to Data Space Reference Architecture Models
DSSC :
- Data Interoperability / Data Exchange: capabilities relating to the actual exchange and sharing of data.
- Data Sovereignty and Trust /
- Data Value Creation Enablers /
- Data, Services and Offering Descriptions: this building block provides data providers with the tools to describe data, services and offerings appropriately, thoroughly, and in a manner that will be understandable by any participant in the data space. It also includes related data policies and how they can be obtained.
- Publication and Discovery: this building block allows data providers to publish the description of their data, services and offerings so that they can be discovered by future potential users, following the FAIR (Findable, Accessible, Interoperable and Reusable) principles as much as possible.
- Value-Added Services: this building block complements the data space enabling services by providing additional services to create value on top of data transactions. These services are structured capabilities to facilitate certain tasks, processes, or functions that these users need, directly or indirectly, for their operations.
*IDS RAM* 4.3.3 Data as an Economic Good
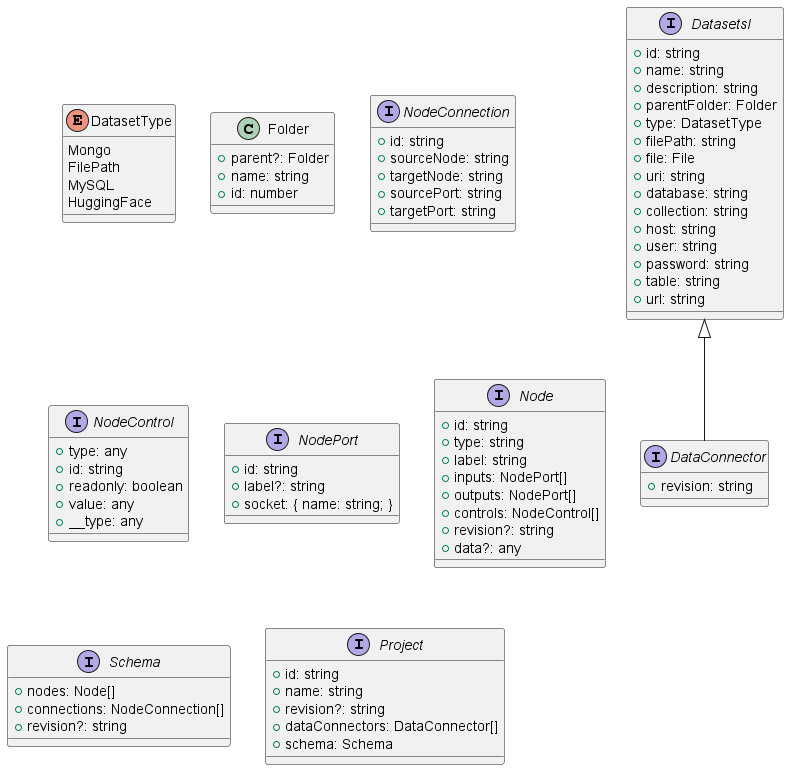
Input / Output Data
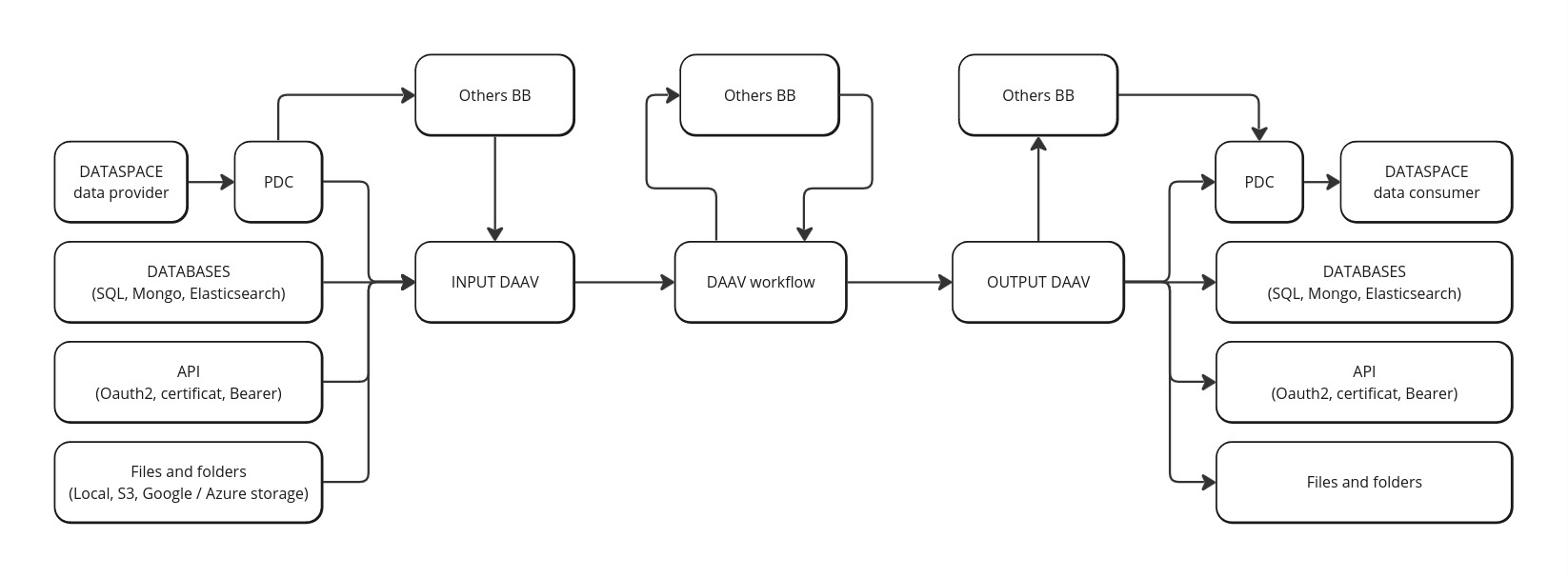
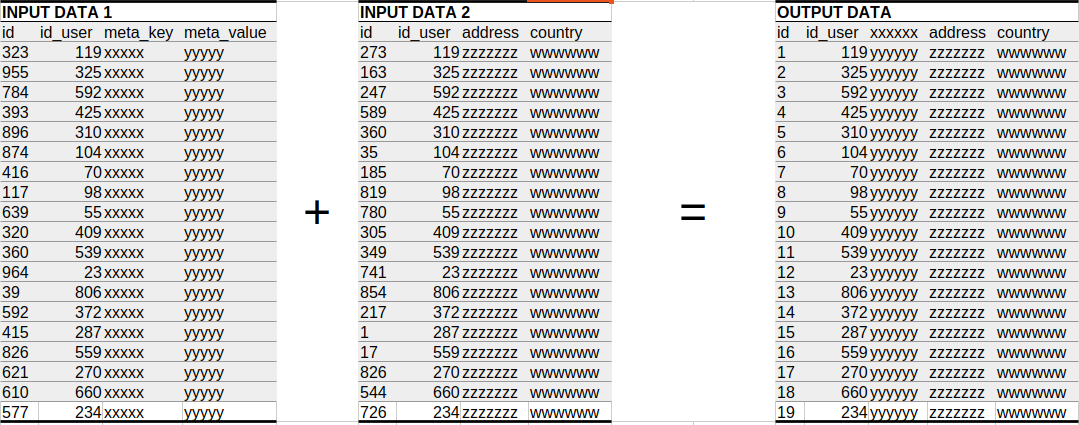
Project interface
Project interface handle all requires information for a DAAV project. The front-end can import and export json content who follows this structure.
The back-end can execute the workflow describe in this structure. Inside we have Data Connectors required to connect to a datasource.
A workflow is represented by nodes (Node) with input and output (NodePort) who can be connected. All nodes are divides in three group :
- Input Node for data sources.
- Transform node to manipulate data.
- Output node to export newly created data.
This may be for a complete run, or simply to test a single node in the chain to ensure hierarchical dependency between connected nodes.
Architecture
Front-end worflow editor class diagram
This diagram describes the basic architecture of the front-end, whose purpose is to model a set of tools for the user, where he can build a processing chain.
This is based on Rete.js, a framework for creating processing-oriented node-based editors.
A workflow is a group of nodes connected by ports (input/output) each ports have a socket type who define the data format which can go through and so define connection rules between node.

Example of a node base editor with nodes and inside inputs and/or output and a colored indicator to visualize its status.
Back-end workflow class diagram
The back-end class, which reconstructs a representation of the defined workflow and executes the processing chain, taking dependencies into account.
For each node, we know its type, and therefore its associated processing, as well as its inputs and outputs, and the internal attributes defined by the user via the interface.

Dynamic Behaviour
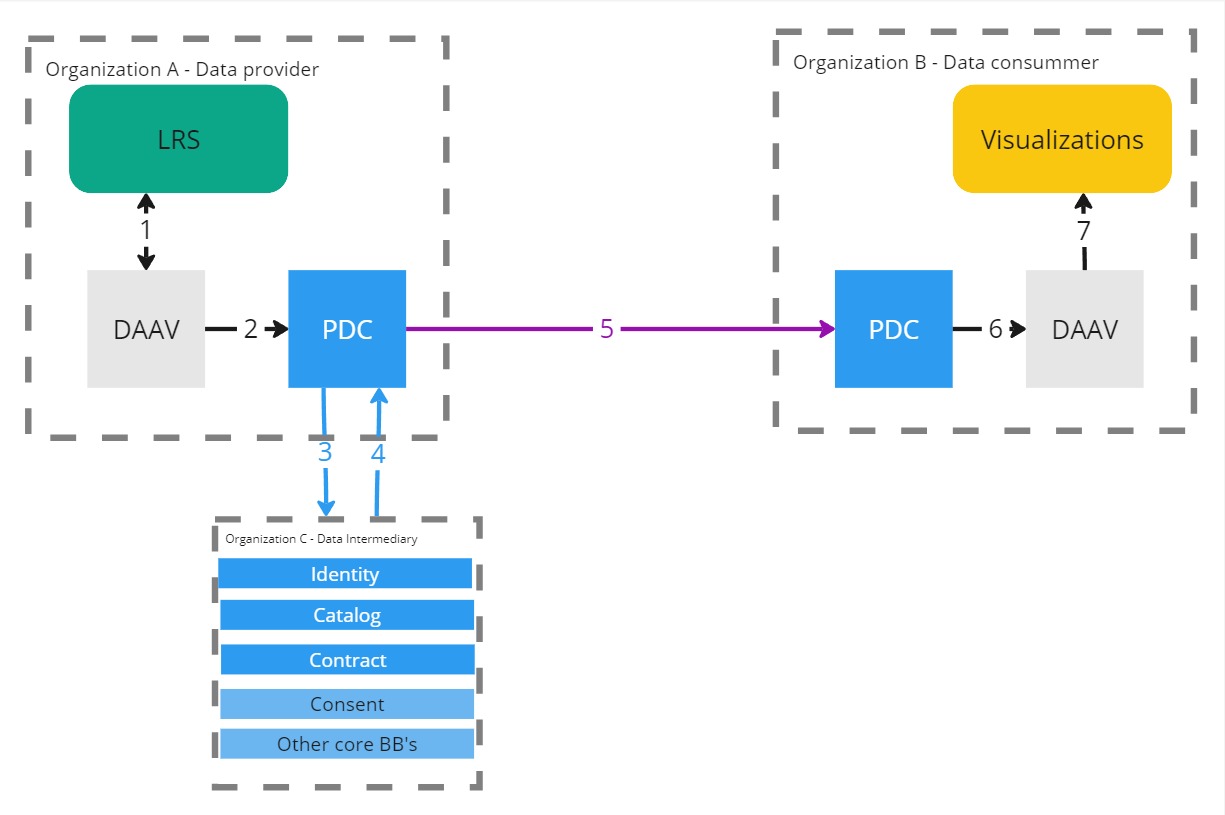
The sequence diagram shows how the component communicates with other components.
---
title: Sequence Diagram Example (Connector Data Exchange)
---
sequenceDiagram
participant i1 as Input Data Block (Data Source)
participant ddvcon as PDC
participant con as Contract Service
participant cons as Consent Service
participant dpcon as Data Provider Connector
participant dp as Participant (Data Provider)
participant i2 as Transformer Block
participant i3 as Merge Block
participant i4 as Output Data Block
participant enduser as End User
i1 -) ddvcon:: Trigger consent-driven data exchange<br>BY USING CONSENT
ddvcon -) cons: Verify consent validity
cons -) con: Verify contract signature & status
con --) cons: Contract verified
cons -) ddvcon: Consent verified
ddvcon -) con: Verify contract & policies
con --) ddvcon: Verified contract
ddvcon -) dpcon: Data request + contract + consent
dpcon -) dp: GET data
dp --) dpcon: Data
dpcon --) ddvcon: Data
ddvcon --) i1: Data
i1 -) i2: Provide data connection or data
Note over i2 : setup of transformation
i2 -) i3: Provide data
Note over i3 : setup merge with another data source
i3 -) i4: Provide data
Note over i4 : new data is available
enduser -) i4: Read file directly from local filesystem
enduser -) i4: Read file through SFTP protocol
enduser -) i4: Read data through REST API
enduser -) i4: Read data through database connector
---
title: Node status - on create or update
---
stateDiagram-v2
classDef Incomplete fill:yellow
classDef Complete fill:orange
classDef Valid fill:green
classDef Error fill:red
[*] --> Incomplete
Incomplete --> Complete: parameters are valid
state fork_state <<choice>>
Complete --> fork_state : Backend execution
fork_state --> Valid
fork_state --> Error
#state fork_state2 <<choice>>
#Error --> fork_state2 : User modify connection/parameter
#fork_state2 --> Complete
#fork_state2 --> Incomplete
class Incomplete Incomplete
class Complete Complete
class Valid Valid
class Error Error
Backend Node Execute : Node mother class function "execute" Each child class have its function "Process" with specific treatment.
Inside a workflow a recursive pattern propagate the execution following parents nodes.
---
title: Backend - Node class function "Execute"
---
stateDiagram-v2
classDef Incomplete fill:yellow
classDef Complete fill:orange
classDef Valid fill:green
classDef Error fill:red
state EachInput {
[*] --> ParentNodeStatus
ParentNodeStatus --> ParentNodeValid
ParentNodeStatus --> ParentNodeComplete
ParentNodeStatus --> ParentNodeIncomplete
ParentNodeIncomplete --> [*]
ParentNodeValid --> [*]
ParentNodeComplete --> ParentNodeStatus : Parent Node function "Execute"
ParentNodeStatus --> ParentNodeError
ParentNodeError --> [*]
}
[*] --> NodeStatus
NodeStatus --> Complete
NodeStatus --> Incomplete
Incomplete --> [*] : Abort
Complete --> EachInput
state if_state3 <<choice>>
EachInput --> if_state3 : Aggregate Result
if_state3 --> SomeInputIncomplete
if_state3 --> AllInputValid
if_state3 --> SomeInputError
SomeInputIncomplete --> [*] : Abort
AllInputValid --> ProcessNode: function "Process"
SomeInputError --> [*] : Abort
ProcessNode --> Error
ProcessNode --> Valid
Valid --> [*] :Success
Error --> [*] :Error
class Incomplete Incomplete
class SomeInputIncomplete Incomplete
class ParentNodeIncomplete Incomplete
class ParentNodeComplete Complete
class Complete Complete
class Valid Valid
class AllInputValid Valid
class ParentNodeValid Valid
class Error Error
class SomeInputError Error
class ParentNodeError Error
Configuration and deployment settings
Various configuration example :
**.env file :**
MONGO_URI = ''
SQL_HOST = ''
LOG_FILE = "logs/log.txt"
...
**secrets folder (openssl password generated) :**
- secrets/db_root_password
- secrets/elasticsearch_admin
**angular environments :**
- production: true / false
- version : X.X
**python fast api backend config.ini :**
[dev]
DEBUG=True/False
[edge]
master:True/False
cluster=014
What are the limits in terms of usage (e.g. number of requests, size of dataset, etc.)?
# work in progress
Third Party Components & Licenses
- retejs MIT license
- ionic/angular/material MIT license
- FastAPI MIT license
- DuckDB MIT license
- PyArrows Apache License
Implementation Details
Nodes implementation :
All nodes have a front-end implementation where the user can setup its configuration and a back-end implementation to execute the process.
All nodes inherit from the abstract class Nodeblock.
We identify shared functionalities like :
- Front-end : a status component to track the node status with a visual indicator.
- Front-end : a data method to save the current node configuration with user modification.
- Front-end : a run button to execute the node.
- Back-end : An execute function to verify parent status and executed them if possible to finally call her inner logic.
- Back-end : An abstract process function with custom business logic
Inputs Node :
All input nodes inherit from InputDataBlock :
We identify shared functionalities like :
- Front-end : button to test the connection with the data-source with a visual indicator.
- Back-end : An abstract test connection function.
We need one class of input Node for each data-source format (Local file, MySQL, Mongo , API, ...)
For the front-end a factory deduces the correct input instance according to the given source connector sent in parameter.
Node instance exposes one output and its socket type define its format :
- Flat object : Table of data with several columns. Examples : CSV, MySQL results
- Deep object : Collection of data with inner objects.
- xAPI : Deep object who follow xAPI specification.
Connections rules between nodes
Each block input defines a socket, ie. what kind of data it accepts (float, string, array of string, etc…).
On the back-end counterpart class :
“Process” function implement the business logic. In this case, it retrieves data-source information and populate the output with data schemes and data content.
For huge data content we can use a parquet format to store intermediate result physically, likely as a selector shared attribute of InputDataBlock
Each input Node may have rules executed at the request level and a widget in the front-end to setup them.
Outputs Node :
All output nodes inherit from OutputDataBlock.
We need one class of output Node for each format handle by the BB.
Each output block specifies the inputs it can process.
The widgets’ block permits to setup the output and visualizes its status.
On the back-end counterpart class :
One method to execute the node and export a file or launch transactions to fill the destination.
Transform Node :
All nodes called upon to manipulate data inherit from the transformation node.
Transform node can dynamically add input or output based on data manipulated and use widgets to expose parameters for the user.
For complex cases, we can imagine a additional modal window to visualize a sample of the data and provide a convenient interface for describing the desired relationships between data.
Considerations on revision identifiers
The workflow representation can be likened to a tree representation, where each node can have a unique revision ID representing its contents and children.
With this we can have a convenient pattern to compare and identify modifications between two calls on back-end API.
If we use intermediate results with physical records such as parquet files, for example, we can avoid certain processing when a node retains the same revision ID between two calls, and reconstruct only those parts where the user has made changes.
By keeping track of the last revision of the root of a front-end and back-end call, it is also possible to detect desynchronization when several instances of a project are open and so, make the user aware of the risks of overwriting.
OpenAPI Specification
The back-end will expose a swagger OpenAPI description.
For all entity describes we will follow a REST API (Create / Update / Delete).
- User entity represent the end user
- Credential entity represent Auth system linked to user.
- DataConnector represent data-source location
- Project entity represent end user workflow
API output data blocks (GET)
- Expose data from all output data blocks defined.
And around the project all business action :
- Execute a workflow
- Execute a node
- Get input / output data schemes from a node
- Get input / output data example from a node
- ...
Test Specification
The DAAV testing strategy ensures that:
- Functionality is efficient and meets requirements
- Potential risks are under control
- Performance meets expected criteria
- Users can successfully complete their workflows
Test Reproduction
To reproduce (manual) tests, you need to deploy DAAV using Docker or local installation.
Prerequisites
Before testing DAAV, ensure you have:
- Docker and Docker Compose installed (recommended), OR
- Node.js 18+, Python 3.10+, MongoDB for local installation
- Web browser (Chrome, Firefox, Edge, or Safari)
Running Instructions (Docker - Recommended)
- Clone the repository:
git clone https://github.com/Prometheus-X-association/daav.git
cd daav
- Start the services:
docker-compose up -d
-
Wait for services to be ready (30-60 seconds)
-
Access the application:
- Frontend: http://localhost:8080
- Backend API: http://localhost:8081
- API Documentation: http://localhost:8081/docs
- MongoDB: mongodb://admin:admin123@localhost:27017
Default Credentials
- Username:
admin - Password:
Admin123!
Configuration
The default configuration should work out-of-the-box. For customization:
- Backend environment variables: See
backendApi/.env.example - Frontend configuration: See
frontendApp/src/environments/
For detailed deployment instructions, see README.md and DOCKER_DEPLOYMENT.md.
Test
The DAAV testing strategy will focus on ensuring the accuracy, reliability, and performance of its functionality. We will use a combination of unit testing, integration testing, component-level testing, and user interface testing. The test environment will reproduce conditions similar to those in production in order to accurately validate BB behavior. Acceptance criteria will be defined based on user stories, functional requirements, and performance criteria.
Summary of tests:
- Validate requirements and potential risks
- Testing independent features
- Internal unit tests (pytest, karma/jasmine)
- Component-level testing (performance)
- Manual usage scenarios
- Comprehensive test definitions
Validate Requirements and Potential Risks
Tests to validate functional requirements and mitigate potential risks identified in the design phase.
| Test ID | Description | Prerequisites | Test | Status | Test Case |
|---|---|---|---|---|---|
| System Health & Infrastructure | |||||
| SYS-001 | Backend API health check | DAAV backend deployed and accessible | GET /health - Verify HTTP 200, JSON response with status, app_name, version |
✅ Manual test | Test Case 0 |
| SYS-002 | API documentation accessibility | Backend running | Navigate to /docs - Verify Swagger UI loads with all endpoints |
✅ Manual test | Test Case 1 |
| Authentication & User Management | |||||
| AUTH-001 | User registration with valid credentials | Application is running. No existing user with same username/email | Username: testuser, Email: testuser@example.com, Password: TestPass123!, Full Name: Test User - Verify account created, can login |
✅ Unit tests | test_auth_service.py, test_user_service.py |
| AUTH-002 | User login with valid credentials | User account exists (username admin, password Admin123!) |
Login with valid credentials - Verify access_token and refresh_token returned | ✅ Both (manual + unit) | Test Case 2, test_auth_service.py |
| AUTH-003 | User login with invalid credentials | Application is running | Login with username admin, password wrongpassword - Verify HTTP 401, error message |
✅ Unit tests | test_auth_service.py |
| AUTH-004 | Password reset flow | User exists with email, email service configured | Request password reset for testuser@example.com - Verify reset token generated |
⚠️ Partial (unit only) | test_auth_service.py, test_email_service.py |
| AUTH-005 | Change password for authenticated user | User is logged in with valid access token | Change from Admin123! to NewAdmin123! - Verify new password works, old doesn't |
✅ Unit tests | test_auth_service.py |
| AUTH-006 | Token refresh using valid refresh token | User has valid refresh token | Use refresh token - Verify new access and refresh tokens generated | ✅ Unit tests | test_auth_service.py |
| AUTH-007 | Access protected resource without authentication | Application is running | Request to /auth/me without Authorization header - Verify HTTP 401 |
✅ Unit tests | test_auth_service.py |
| AUTH-008 | Admin creates new user | Admin user is logged in | Create user: username newuser, email newuser@example.com, role user - Verify user created |
✅ Unit tests | test_user_service.py |
| AUTH-009 | Admin deactivates user account | Admin logged in, target user exists and is active | Deactivate user by ID - Verify user cannot login, data preserved | ✅ Unit tests | test_user_service.py |
| AUTH-010 | Admin activates deactivated user | Admin logged in, target user exists and is deactivated | Activate user by ID - Verify user can login again | ✅ Unit tests | test_user_service.py |
| AUTH-011 | Non-admin attempts admin operation | Regular user is logged in (not admin) | Attempt to create user as non-admin - Verify HTTP 403, operation denied | ✅ Unit tests | test_auth_service.py |
| Dataset Management | |||||
| DATA-001 | Create file dataset (CSV/JSON) | User authenticated, file exists | Name: test-dataset, Type: file, File: sample.csv or data.json - Verify dataset created, appears in list, structure preserved |
✅ Both (manual + unit) | Test Case 3, test_dataset_service.py |
| DATA-003 | Create file dataset (Parquet) | User authenticated, Parquet file exists | Name: parquet-dataset, Type: file, File: data.parquet - Verify schema readable |
✅ Unit tests | test_dataset_service.py |
| DATA-004 | Create MySQL dataset connection | User authenticated, MySQL database accessible | Name: mysql-dataset, Host: db.example.com, Port: 3306, Database: testdb, Table: users - Verify connection created, credentials encrypted |
✅ Unit tests | test_dataset_service.py |
| DATA-005 | Create MongoDB dataset connection | User authenticated, MongoDB accessible | Name: mongo-dataset, URI: mongodb://localhost:27017, Database: testdb, Collection: users - Verify connection successful |
✅ Unit tests | test_dataset_service.py |
| DATA-006 | Create API dataset connection | User authenticated, External API accessible | Name: api-dataset, URL: https://api.example.com/data, Method: GET, Headers with auth - Verify API callable |
✅ Unit tests | test_dataset_service.py |
| DATA-007 | Create Elasticsearch dataset | User authenticated, Elasticsearch accessible | Name: elastic-dataset, URL: http://localhost:9200, Index: test-index - Verify index queryable |
✅ Unit tests | test_dataset_service.py |
| DATA-008 | Create PTX dataset connection | User authenticated, PDC accessible | Name: ptx-dataset, Type: ptx, PDC URL, Bearer token - Verify catalog retrievable |
✅ Unit tests | test_dataset_service.py, test_pdc_service.py |
| DATA-009 | Upload file through API | User authenticated, file size within limits | Upload upload.csv (< 100MB), Folder: datasets - Verify file uploaded, path returned, user isolated |
✅ Unit tests | test_dataset_service.py |
| DATA-010 | Upload file exceeding size limit | User authenticated | Upload file > 100MB - Verify HTTP 413, appropriate error message | ✅ Unit tests | test_dataset_service.py |
| DATA-011 | Retrieve dataset content | User authenticated, dataset exists, user has access | Dataset ID, Pagination: page 1, limit 100 - Verify content returned, pagination works | ✅ Both (manual + unit) | Test Case 4, test_dataset_service.py |
| DATA-012 | Edit dataset configuration | User authenticated, user owns dataset | Dataset ID, New name: updated-dataset - Verify changes persisted |
✅ Unit tests | test_dataset_service.py |
| DATA-013 | Delete dataset | User authenticated, user owns dataset | Dataset ID - Verify deleted, no longer in list, files cleaned up | ✅ Unit tests | test_dataset_service.py |
| DATA-014 | Access dataset without permission | User authenticated, dataset belongs to another user | Attempt to access other user's dataset - Verify HTTP 403, access denied | ✅ Unit tests | test_dataset_service.py |
| DATA-015 | Share dataset with another user | User owns dataset, target user exists | Dataset ID, Target User ID, Permission: read - Verify share successful, target can access |
✅ Unit tests | test_dataset_service.py |
| DATA-016 | Unshare dataset | Dataset is shared, user is owner | Dataset ID, Target User ID - Verify share removed, target loses access | ✅ Unit tests | test_dataset_service.py |
| Workflow Creation & Management | |||||
| WF-001 | Create empty workflow | User authenticated | Name: test-workflow, Revision: 1.0, Schema: empty - Verify workflow ID returned, appears in list |
✅ Both (manual + unit) | Test Case 6, test_workflow_service.py |
| WF-002 | Create workflow with single input node | User authenticated, dataset exists | Name: simple-workflow, Nodes: DataFileBlock, Dataset ID - Verify node configured correctly |
✅ Both (manual + unit) | Test Case 5, 6, test_workflow_service.py |
| WF-003 | Create workflow with input-transform-output chain | User authenticated, dataset exists | Nodes: DataFileBlock → FilterTransform → FileOutput - Verify all connected, executable | ✅ Unit tests | test_workflow_service.py |
| WF-004 | Save workflow with complex transformations | User authenticated, multiple datasets exist | Workflow with 10+ nodes (Filter, Flatten, Merge, Join) - Verify all configs preserved | ✅ Unit tests | test_workflow_service.py |
| WF-005 | Update existing workflow | User authenticated, workflow exists, user owns it | Workflow ID, updated schema with new nodes - Verify updated, revision tracked | ✅ Unit tests | test_workflow_service.py |
| WF-006 | Delete workflow | User authenticated, user owns workflow | Workflow ID - Verify deleted, no longer in list, outputs cleaned | ✅ Unit tests | test_workflow_service.py |
| WF-007 | Retrieve workflow by ID | User authenticated, user has access | Workflow ID - Verify data returned, schema complete | ✅ Unit tests | test_workflow_service.py |
| WF-008 | List all user workflows | User authenticated, user has workflows | User access token - Verify only accessible workflows shown | ✅ Unit tests | test_workflow_service.py |
| WF-009 | Export workflow as JSON | Workflow exists, user has access | Workflow ID - Verify complete JSON returned, all nodes and connections | ✅ Unit tests | test_workflow_service.py |
| WF-010 | Import workflow from JSON | User authenticated, valid JSON provided | Valid workflow JSON - Verify imported, new ID assigned, nodes restored | ✅ Unit tests | test_workflow_service.py |
| Workflow Execution | |||||
| EXEC-001 | Execute simple workflow (CSV → File) | Valid workflow with CSV input and file output | Workflow ID - Verify executes, output file created, transformation correct | ✅ Both (manual + unit) | Test Case 7, test_workflow.py, test_node.py |
| EXEC-002 | Execute workflow with filter transformation | Workflow with filter node, input data available | Workflow ID, Filter: age > 18 - Verify only filtered records in output |
✅ Unit tests | test_filter_transform.py |
| EXEC-003 | Execute workflow with flatten transformation | Workflow with nested JSON input, flatten node | Workflow ID, nested JSON data - Verify nested structures flattened | ✅ Unit tests | test_flatten_transform.py |
| EXEC-004 | Execute workflow with merge transformation | Workflow merges two datasets, both available | Workflow ID, Dataset A + B, Merge key: id - Verify merged correctly |
✅ Unit tests | test_merge_transform.py |
| EXEC-005 | Execute workflow with join transformation | Workflow joins two datasets, join configured | Workflow ID, Left join on user_id - Verify join correct, null handling ok |
✅ Unit tests | test_workflow.py |
| EXEC-006 | Execute workflow with multiple transformations | Complex workflow with 5+ transform nodes | Workflow ID - Verify all execute in order, data flows correctly | ✅ Unit tests | test_workflow.py, test_execution_context.py |
| EXEC-007 | Execute workflow with MySQL output | Workflow outputs to MySQL table, DB accessible | Workflow ID, Target table: results - Verify data written, table created if needed |
✅ Unit tests | test_node.py |
| EXEC-008 | Execute workflow with MongoDB output | Workflow outputs to MongoDB, DB accessible | Workflow ID, Collection: results - Verify data written, documents structured |
✅ Unit tests | test_node.py |
| EXEC-009 | Execute workflow with API output | Workflow configured with custom API endpoint | Workflow ID, API URL: /api/custom-path - Verify endpoint exposed, returns results |
✅ Unit tests | test_workflow.py |
| EXEC-010 | Execute incomplete workflow | Workflow has disconnected nodes, incomplete config | Incomplete workflow ID - Verify fails gracefully, error indicates missing connections | ✅ Unit tests | test_workflow.py |
| EXEC-011 | Execute workflow with invalid data | Workflow expects specific schema, input doesn't match | Workflow ID, invalid input - Verify validation error, schema mismatch indicated | ✅ Unit tests | test_node.py |
| EXEC-012 | Execute workflow recursively (dependencies) | Workflow with dependent nodes, parents incomplete | Execute specific node - Verify parents execute first, dependencies resolved | ✅ Unit tests | test_workflow.py, test_execution_context.py |
| API Endpoints & Data Exposure | |||||
| API-001 | Access custom API endpoint | Workflow with ApiOutput, custom path configured | GET /api/custom-path - Verify data returned, workflow executed if needed |
✅ Unit tests | test_workflow.py |
| API-002 | Access API endpoint with authentication token | ApiOutput configured with token auth | GET /api/secure-path, Header: X-API-Key: <token> - Verify auth works, invalid rejected |
✅ Unit tests | test_workflow.py |
| API-003 | Access API endpoint with query filters | ApiOutput endpoint exposed, data available | GET /api/data?filter[age][operator]=>&filter[age][value]=18 - Verify filtered data returned |
✅ Unit tests | test_workflow.py |
| API-004 | Access workflow output by workflow ID | Workflow executed, output generated | GET /api/workflow/<id>, with auth - Verify latest execution results returned |
✅ Unit tests | test_workflow.py |
| API-005 | Access non-existent API endpoint | No workflow configured for path | GET /api/non-existent - Verify HTTP 404, appropriate error |
✅ Unit tests | test_workflow.py |
| API-006 | Execute and retrieve workflow via API | Valid workflow exists | POST /workflows/execute/<id> - Verify executes, results available |
✅ Unit tests | test_workflow_service.py |
| Prometheus-X Integration (PTX) | |||||
| PTX-001 | Create PTX dataset connection | User authenticated, PDC connector accessible | Name: ptx-connector, PDC URL, Token - Verify connection created, token secured |
✅ Unit tests | test_pdc_service.py |
| PTX-002 | Retrieve catalog from PTX connection | PTX dataset configured, PDC accessible | Connection ID - Verify catalog retrieved, offerings/resources listed | ✅ Unit tests | test_pdc_service.py |
| PTX-003 | Get data resources from PTX | PTX connection exists, catalog has resources | Connection ID - Verify resources listed, metadata complete | ✅ Unit tests | test_pdc_service.py |
| PTX-004 | Update data resource URL in PTX | PTX connection exists, resource exists in catalog | Connection ID, Resource ID, New URL - Verify URL updated in PDC | ✅ Unit tests | test_pdc_service.py |
| PTX-005 | Execute service chain workflow | Service chain configured, workflow assigned | POST /ptx/executeChainService, Headers with chain ID, Payload - Verify executed in chain context |
✅ Unit tests | test_pdc_service.py |
| PTX-006 | Trigger data exchange via PTX | PTX connection configured, exchange endpoint exists | Connection ID, Data exchange config - Verify exchange triggered, response handled | ✅ Unit tests | test_pdc_service.py |
| PTX-007 | Store and retrieve service chain data | Service chain ID exists, data stored temporarily | Service Chain ID, Store payload - Verify data stored, retrievable, cleaned after | ✅ Unit tests | test_pdc_service.py |
| PTX-008 | Access PDC output endpoint | Workflow with PdcOutput, custom URL configured | GET /output/<custom_path>, Headers: M2M credentials - Verify workflow executes, output returned |
✅ Unit tests | test_pdc_service.py |
| PTX-009 | Receive pushed data from PDC | PDC configured to push data, endpoint listening | POST /ptx/pdcInput, Data payload from PDC - Verify data received, processed, acknowledged |
✅ Unit tests | test_pdc_service.py |
| Security & Access Control | |||||
| SEC-001 | Path traversal prevention in file upload | User authenticated | Upload file with name: ../../etc/passwd - Verify rejected/sanitized, no traversal |
✅ Unit tests | test_path_security.py |
| SEC-002 | File extension validation | User authenticated | Upload file: malicious.exe - Verify rejected, only allowed extensions accepted |
✅ Unit tests | test_path_security.py |
| SEC-003 | File size limit enforcement | User authenticated | Upload 150MB file (limit 100MB) - Verify HTTP 413, limit enforced before full upload | ✅ Unit tests | test_security_middleware.py |
| SEC-004 | SQL injection prevention | MySQL dataset configured | Query with injection: '; DROP TABLE users; -- - Verify prevented, parameterized, no damage |
✅ Unit tests | test_dataset_service.py |
| SEC-005 | XSS prevention in user inputs | User creates dataset with name | Name: <script>alert('XSS')</script> - Verify sanitized, script escaped/removed |
✅ Unit tests | test_security_middleware.py |
| SEC-006 | Rate limiting on API endpoints | Public API endpoint configured | 100 requests in 10 seconds to same endpoint - Verify HTTP 429, limit triggered | ⚠️ Partial (unit only) | test_security_middleware.py |
| SEC-007 | CORS policy enforcement | Frontend on different origin | API request from http://evil.com - Verify blocked if not allowed, CORS enforced |
✅ Unit tests | test_security_middleware.py |
| SEC-008 | Sensitive data encryption | User creates dataset with password | Password: MySecretPass123 - Verify encrypted in DB, not in API responses |
✅ Unit tests | test_dataset_service.py |
| SEC-009 | User data isolation | Two users with same filename | User A uploads data.csv, User B uploads data.csv - Verify stored separately, isolation maintained |
✅ Unit tests | test_path_security.py |
| SEC-010 | Token expiration enforcement | Access token expired (> 60 min old) | Request with expired token - Verify HTTP 401, must refresh/re-login | ✅ Unit tests | test_auth_service.py |
| Data Processing & Transformations | |||||
| PROC-001 | Process CSV file with headers | CSV file with headers uploaded | File with columns: name,age,city - Verify parsed, headers detected, names preserved |
✅ Unit tests | test_dataset_service.py |
| PROC-002 | Process CSV file without headers | CSV file without headers | Headerless CSV data - Verify parsed, auto-generated column names | ✅ Unit tests | test_dataset_service.py |
| PROC-003 | Process JSON array | JSON file with array of objects | [{id: 1, name: "A"}, {id: 2, name: "B"}] - Verify array parsed, objects accessible |
✅ Unit tests | test_dataset_service.py |
| PROC-004 | Process nested JSON | JSON with nested structures | {user: {profile: {age: 25}}} - Verify nested preserved, dot notation accessible |
✅ Unit tests | test_dataset_service.py, test_flatten_transform.py |
| PROC-005 | Process Parquet file | Parquet file uploaded | Parquet with schema and data - Verify schema read, data queryable, types preserved | ✅ Unit tests | test_dataset_service.py |
| PROC-006 | Process Excel file (.xlsx) | Excel file uploaded with multiple sheets | Excel with 3 sheets - Verify all detected, sheet selection available | ✅ Unit tests | test_dataset_service.py |
| PROC-007 | Handle missing values in data | Dataset with null/empty values | Data with nulls and empty strings - Verify handled gracefully, distinguished | ✅ Unit tests | test_node.py, test_filter_transform.py |
| PROC-008 | Handle large dataset (1M+ rows) | Large CSV file (> 1 million rows) | 1M row CSV - Verify processed efficiently, pagination works, no timeout | ✅ Unit tests | test_dataset_service.py |
| PROC-009 | Convert between data formats | Input CSV, output Parquet | CSV → Parquet conversion - Verify successful, data integrity maintained | ✅ Unit tests | test_node.py |
| PROC-010 | Aggregate data (groupBy) | Dataset with groupable data, transform with aggregate | Group by category, aggregate sum(amount) - Verify grouping correct, aggregation accurate |
✅ Unit tests | test_workflow.py |
| PROC-011 | Sort data | Dataset with unsorted data, sort transformation | Sort by age DESC, name ASC - Verify multi-column sort works, order correct |
✅ Unit tests | test_workflow.py |
| PROC-012 | Remove duplicates | Dataset with duplicate rows | Deduplicate on columns: id - Verify duplicates removed, unique rows remain |
✅ Unit tests | test_workflow.py |
| Error Handling & Edge Cases | |||||
| ERR-001 | Handle malformed JSON input | User uploads JSON file | Invalid JSON: {broken: syntax - Verify error caught, helpful message, line number if possible |
✅ Unit tests | test_dataset_service.py |
| ERR-002 | Handle corrupt file upload | User uploads corrupted file | Corrupted CSV file - Verify error detected, upload fails with reason | ✅ Unit tests | test_dataset_service.py |
| ERR-003 | Handle database connection failure | MySQL dataset configured, database is down | Execute workflow with MySQL input - Verify connection error caught, clear error | ✅ Unit tests | test_dataset_service.py |
| ERR-004 | Handle external API timeout | API dataset configured, API slow/unresponsive | Workflow with API call (30s+ response) - Verify timeout handled, configurable, clear error | ✅ Unit tests | test_dataset_service.py |
| ERR-005 | Handle missing required fields | Create dataset without required field | Dataset without name field - Verify HTTP 422, required fields listed |
✅ Unit tests | test_dataset_service.py, test_workflow_service.py |
| ERR-006 | Handle concurrent workflow edits | Two users edit same workflow simultaneously | User A and B save workflow at same time - Verify conflict detected, no corruption | ⚠️ Partial (unit only) | test_workflow_service.py |
| ERR-007 | Handle workflow circular dependencies | User creates workflow with circular connections | Node A → Node B → Node A - Verify detected, validation prevents save, error explains | ✅ Unit tests | test_workflow.py |
| ERR-008 | Handle insufficient disk space | Server disk space full, file upload attempted | Upload large file when disk full - Verify HTTP 507, graceful degradation | ⚠️ Not implemented | test_dataset_service.py |
| ERR-009 | Handle memory exhaustion on large data | Very large dataset processing | Process 10GB+ file - Verify memory limit respected, streaming/chunking, OOM error if needed | ✅ Unit tests | test_dataset_service.py, test_workflow.py |
| ERR-010 | Handle invalid credentials in dataset | MySQL dataset with wrong password | Credentials: user admin, wrong password - Verify auth error caught, clear message, no leak |
✅ Unit tests | test_dataset_service.py |
Testing Independent Features
Small manual tests to prove individual features work correctly.
Test Case 0: Backend Health Check
Objective: Ensure the DAAV backend service is running and responding correctly.
Precondition: DAAV backend service is deployed and accessible.
Steps:
- Open a web browser or terminal
- Send a GET request to
http://localhost:8081/health - Verify the response status code is
200 OK - Verify the response body contains the expected JSON
Expected Result:
{
"status": "healthy",
"app_name": "DAAV Backend API",
"environment": "production",
"version": "2.0.0"
}
Result: Validated
Test Case 1: Verify API Documentation Access
Objective: Ensure the Swagger API documentation is accessible.
Precondition: Backend is running.
Steps:
- Open browser
- Navigate to
http://localhost:8081/docs - Verify Swagger UI loads
Expected Result: Swagger documentation page displays with all available endpoints.
Result: Validated
Test Case 2: Verify User Authentication
Objective: Ensure users can log in with valid credentials.
Precondition: Application is running.
Steps:
- Access the login page
- Enter username:
admin - Enter password:
Admin123! - Click "Login" button
Expected Result: User is logged in and redirected to the main dashboard.
Result: Validated
Test Case 3: Verify Dataset Creation
Objective: Ensure datasets can be created with file upload (JSON format).
Precondition:
- DAAV interface is accessible
- User is logged in
- A valid JSON file is available (test-files/prize.json)
Steps:
- Access DAAV interface at
http://localhost:8080 - Navigate to the "Datasets" section
- Click on "Add Dataset" button
- Select "File" as type
- Upload the JSON file
- Enter dataset name
- Confirm creation
Expected Result: Dataset is created and appears in the list.
Result: Validated
Test Case 4: Verify Dataset Content Retrieval
Objective: Ensure dataset content can be retrieved and displayed.
Precondition:
- User is logged in
- Dataset exists
Steps:
- Select a dataset from the list
- Click to view dataset details
- Observe data preview
Expected Result: Dataset content is displayed correctly with proper formatting.
Result: Validated
Test Case 5: Verify Node Connection in Workflow Editor
Objective: Ensure nodes can be connected in the visual workflow editor.
Precondition: Workflow editor is open with at least two compatible nodes.
Steps:
- Click on output port of first node
- Drag connection to input port of second node
- Release to create connection
Expected Result: Visual connection line appears between nodes and connection is saved.
Result: Validated
Test Case 6: Verify Workflow Creation
Objective: Ensure a workflow can be created and saved.
Precondition: At least one dataset exists.
Steps:
- Navigate to "Transformation" tab
- Click on "New Workflow"
- Drag and drop a DataFileBlock node
- Configure the block by selecting the dataset
- Add a FlattenTransform node
- Add a FileOutput node
- Configure the output filename
- Connect the blocks
- Save the workflow
Expected Result: Workflow is saved with a unique ID.
Result: Validated
Test Case 7: Verify Workflow Execution
Objective: Ensure a workflow can be executed successfully.
Precondition: A valid workflow exists.
Steps:
- Select a saved workflow
- Click the play button
- Observe execution progress
Expected Result: Workflow executes without error and produces expected result.
Result: Validated
In conclusion, all the core functional tests are validated.
Manual Usage Scenarios
Using real-world personas and use cases, we established several detailed test scenarios that demonstrate end-to-end functionality.
Persona 1: Data Analyst - Paul (Single Organization)
Profile:
- Name: Paul
- Role: Data Analyst at EdTech Company
- Needs: Aggregate student performance data from multiple sources
- Technical Level: Intermediate
- Organization: Single company with one data source
Test Scenario 1: Paul creates a data aggregation workflow
Context: Paul needs to combine CSV files from different departments to create a unified dashboard.
Prerequisites:
- DAAV deployed and accessible
- User account created:
- Username:
paul - Password:
DataAnalyst123! - Role:
user
- Username:
- Two CSV files available:
- test-files/students_scores.csv (columns: student_id, name, math_score, science_score)
- test-files/students_attendance.csv (columns: student_id, attendance_rate)
Steps:
-
Login:
- Navigate to
http://localhost:8080 - Enter username:
paul - Enter password:
DataAnalyst123! - Click "Login"
- Navigate to
-
Upload CSV files:
- Go to "Datasets" tab
- Click "Add Dataset"
- Select "File" type
- Upload
students_scores.csv - Name it:
student-scores - Click "Save"
- Repeat for
students_attendance.csv, name it:student-attendance
-
Create workflow:
- Navigate to "Workflows" tab
- Click "New Workflow"
- Name workflow:
student-performance-report
-
Build data pipeline:
- Drag two "DataFileBlock" nodes to canvas
- Configure first node: select
student-scoresdataset - Configure second node: select
student-attendancedataset - Drag "MergeTransform" node to canvas
- Connect both DataFileBlock outputs to MergeTransform inputs
- Configure merge: join on
student_idcolumn - Drag "FileOutput" node to canvas
- Connect MergeTransform output to FileOutput input
- Configure output: filename
student_report.parquet
-
Execute workflow:
- Click "Save" to save workflow
- Click "Execute" button
- Wait for execution to complete
-
Verify results:
- Check execution status shows "Success"
- Download output file
student_report.parquet - Verify merged data contains all columns from both sources
Expected Result:
- Workflow executes successfully
- Output file contains merged data with columns: student_id, name, math_score, science_score, attendance_rate
- All student records are present with matching attendance data
Validation: Test Scenario 1 Validated
Persona 2: AI Developer - Christophe (Multiple Data Sources)
Profile:
- Name: Christophe
- Role: AI/ML Engineer
- Needs: Prepare training data from multiple data sources
- Technical Level: Advanced
- Organization: Works with multiple data providers
Test Scenario 2: Christophe prepares ML training data
Context: Christophe needs to combine data from a public REST API and a local JSON file, apply transformations, and export to Parquet format for ML training.
Prerequisites:
- DAAV deployed and accessible
- User account created:
- Username:
christophe - Password:
MLEngineer123! - Role:
user
- Username:
- Local JSON file available: test-files/ml_features.json (contains: id, feature1, feature2, category)
Steps:
-
Login:
- Access DAAV at
http://localhost:8080 - Enter username:
christophe - Enter password:
MLEngineer123! - Click "Login"
- Access DAAV at
-
Create API dataset:
- Go to "Datasets"
- Click "Add Dataset"
- Select "API" type
- Name:
api-users - URL:
https://jsonplaceholder.typicode.com/users - Method: GET
- Headers: Leave empty (no authentication needed)
- Save dataset
- Click "Test Connection" to verify API is accessible
-
Upload JSON file:
- Click "Add Dataset"
- Select "File" type
- Upload
ml_features.json - Name it:
ml-features - Click "Save"
-
Build ML data pipeline:
- Navigate to "Workflows" tab
- Click "New Workflow"
- Name workflow:
ml-training-pipeline - Add "DataApiBlock" node
- Configure: select
api-usersdataset - Add "DataFileBlock" node
- Configure: select
ml-featuresdataset - Add "FilterTransform" node
- Configure filter: remove null values
- Add "FlattenTransform" node for nested JSON (from API)
- Add "MergeTransform" node
- Connect both data sources to MergeTransform
- Configure merge: join on
idcolumn - Add "FileOutput" node
- Connect MergeTransform output to FileOutput
- Configure output:
training_data.parquetformat
-
Configure and execute:
- Connect all nodes as described
- Save workflow
- Click "Execute"
- Monitor execution progress
-
Verify results:
- Check execution status shows "Success"
- Download output file
training_data.parquet - Verify merged data contains columns from both sources (id, name, email, feature1, feature2, category)
Expected Result:
- API data from JSONPlaceholder successfully retrieved (10 users)
- Local JSON file data successfully loaded
- Null values are filtered out
- Nested structures from API are flattened
- Data merged on
idcolumn - Output Parquet file ready for ML training
- File schema compatible with common ML libraries (pandas, scikit-learn)
Validation: ✅ Test Scenario 2 Validated
Persona 3: System Administrator - Fatim (Multi-Organization with PDC)
Profile:
- Name: Fatim
- Role: System Administrator
- Needs: Expose data through Prometheus-X dataspace
- Technical Level: Expert
- Organization: Part of Prometheus-X consortium
Test Scenario 3: Fatim configures PDC data exchange
Context: Fatim needs to create a workflow that receives data from a PDC (Prometheus Data Connector), processes it, and exposes it via Prometheus-X service chain.
Prerequisites:
- DAAV deployed with PTX integration
- User account created:
- Username:
fatim - Password:
SysAdmin123! - Role:
admin
- Username:
- PDC connector configured
- Valid PDC credentials and contract
Steps:
-
Login:
- Navigate to
http://localhost:8080 - Enter username:
fatim - Enter password:
SysAdmin123! - Click "Login"
- Navigate to
-
Setup PDC connection:
- Go to "Datasets"
- Click "Add Dataset"
- Select "Prometheus-X (PDC)" type
- Name:
pdc-learning-records - PDC URL:
https://pdc.example.com - Bearer Token:
<valid_token> - Save connection
-
Verify catalog access:
- Click on PDC dataset
- View "Catalog" tab
- Verify service offerings and data resources are listed
- Confirm participant information is displayed
-
Create workflow with PDC:
- Create new workflow:
pdc-data-processing - Add PDC input node (ServiceChainInput)
- Add transformation nodes (Filter, Aggregate)
- Add PDC output node (PdcOutput)
- Configure custom URL:
/api/processed-learning-data
- Create new workflow:
-
Configure service chain:
- In PdcOutput node, configure:
- URL path:
processed-learning-data - Enable M2M authentication
- Set access token
- URL path:
- Save workflow
- In PdcOutput node, configure:
-
Test data exchange:
- Trigger service chain execution
- Send test data through PDC
- Verify workflow receives data
- Check transformation applied correctly
- Verify output endpoint is accessible
-
Verify endpoint access:
- External system sends GET request to:
http://localhost:8081/output/processed-learning-data - With header:
Authorization: Bearer <m2m_token> - Verify transformed data is returned
- External system sends GET request to:
Expected Result:
- PDC connection successfully established
- Catalog data retrieved from PDC
- Workflow processes incoming data from service chain
- Output endpoint exposed with M2M authentication
- External systems can access processed data
- Data exchange follows Prometheus-X protocols
Validation: Test Scenario 3 Validated
Test Scenario 4: Error Handling - Invalid Dataset Connection
Objective: Verify graceful error handling when dataset connection fails.
Context: User configures a MySQL dataset with incorrect credentials.
Steps:
- Create MySQL dataset with wrong password
- Attempt to retrieve data from the dataset
- Observe error handling
Expected Result:
- Clear error message displayed
- Error indicates authentication failure
- No sensitive credentials exposed in error
- Application remains stable
Validation: Test Scenario 4 Validated
Internal Unit Tests
DAAV includes comprehensive automated test suites to ensure code quality and functionality.
Test Execution Information
Internal Unit Tests
Backend (Python/Pytest):
- Test Framework: Pytest
- Test Files:
backendApi/tests/ - Test Categories:
- Services: Auth, User, Dataset, Workflow, PDC, Email, Migration
- Core: Workflow execution, Node processing, Execution context
- Nodes: Input nodes, Transform nodes, Output nodes
- Security: Path validation, Security middleware
- Utils: Helper functions
Commands to run backend tests:
cd backendApi
python -m pytest # Run all tests
python -m pytest tests/services/ # Run service tests
python -m pytest tests/nodes/ # Run node tests
python -m pytest --cov=app --cov-report=html # With coverage
Frontend (Angular/Karma/Jasmine):
- Test Framework: Karma + Jasmine
- Test Files:
frontendApp/src/**/*.spec.ts - Test Categories:
- Components: Workflow editor, Node blocks, UI components
- Services: Dataset service, Workflow service, Auth service
- Guards: Authentication guards
- Utilities
- WIP Components Nodes
Commands to run frontend tests:
cd frontendApp
npm test # Run tests
npm run test:headless # Headless mode
ng test --code-coverage # With coverage
Partners & roles
Profenpoche (BB leader):
- Organize workshops
- Develop backend of DAAV
- Develop frontend of DAAV
Inokufu :
- BB validation
BME, cabrilog and Ikigaï are also partners available for beta-testing.
Usage in the dataspace
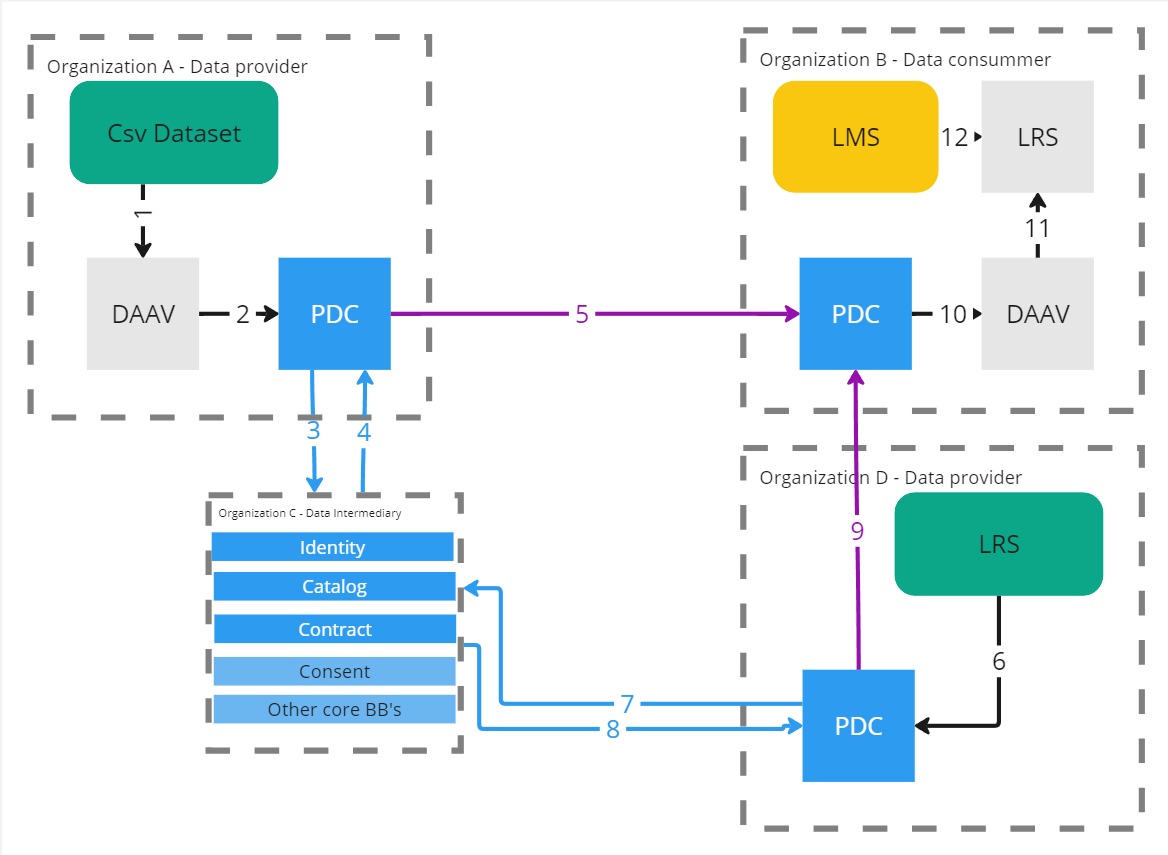
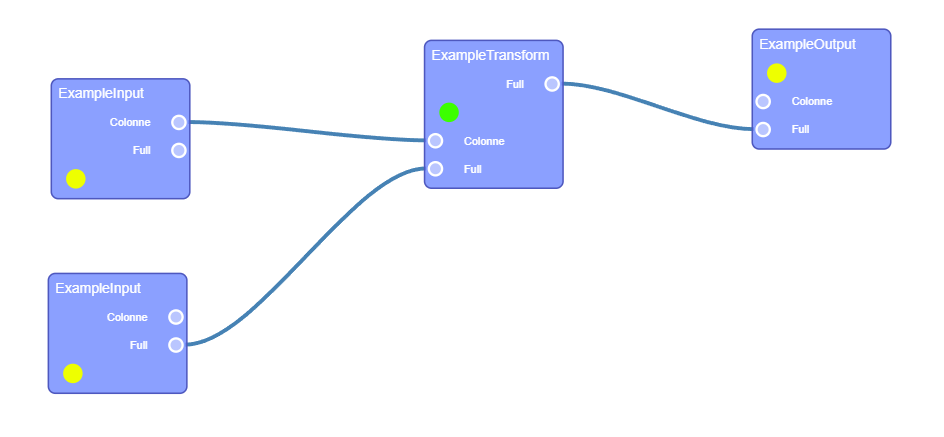
The Daav building block can be used as a data transformer to build new datasets from local data or from prometheus dataspace.
The output can also be share on prometheus dataspace.
Example 1
 Example 2
Example 2
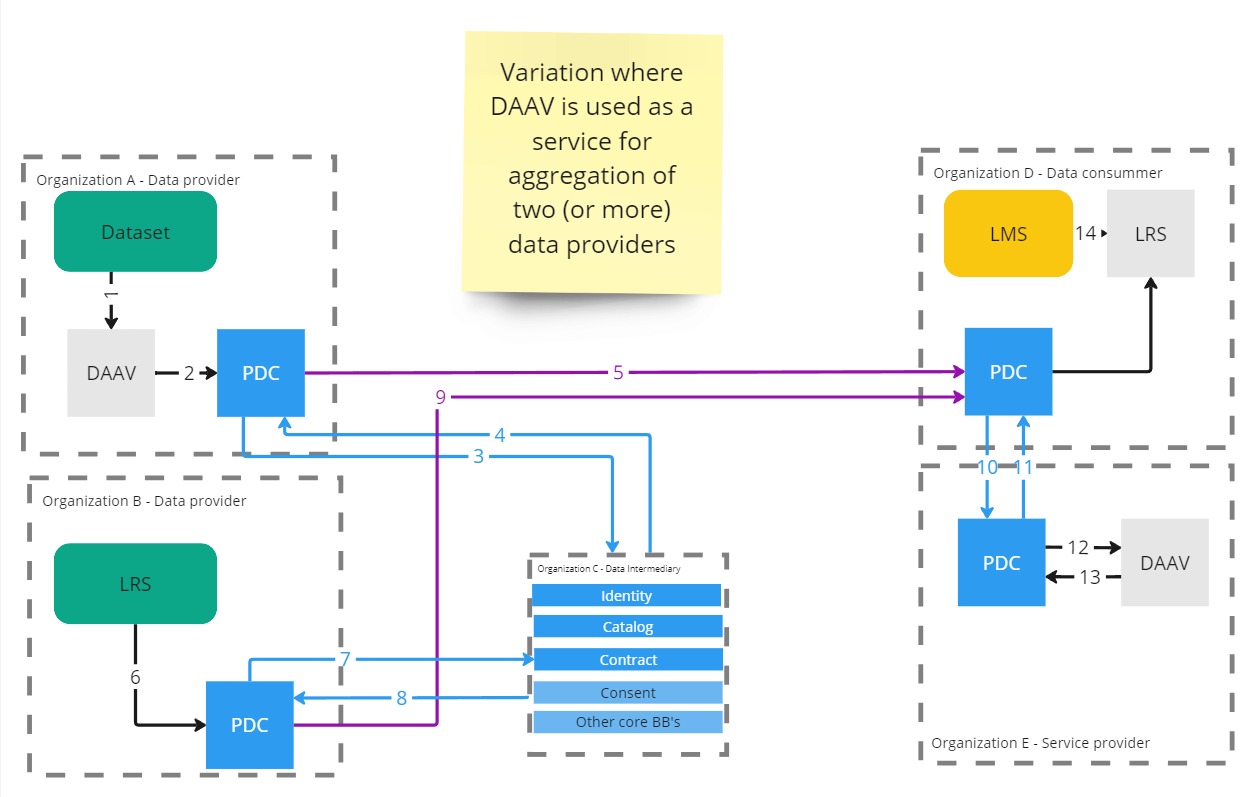 Example 3
Example 3
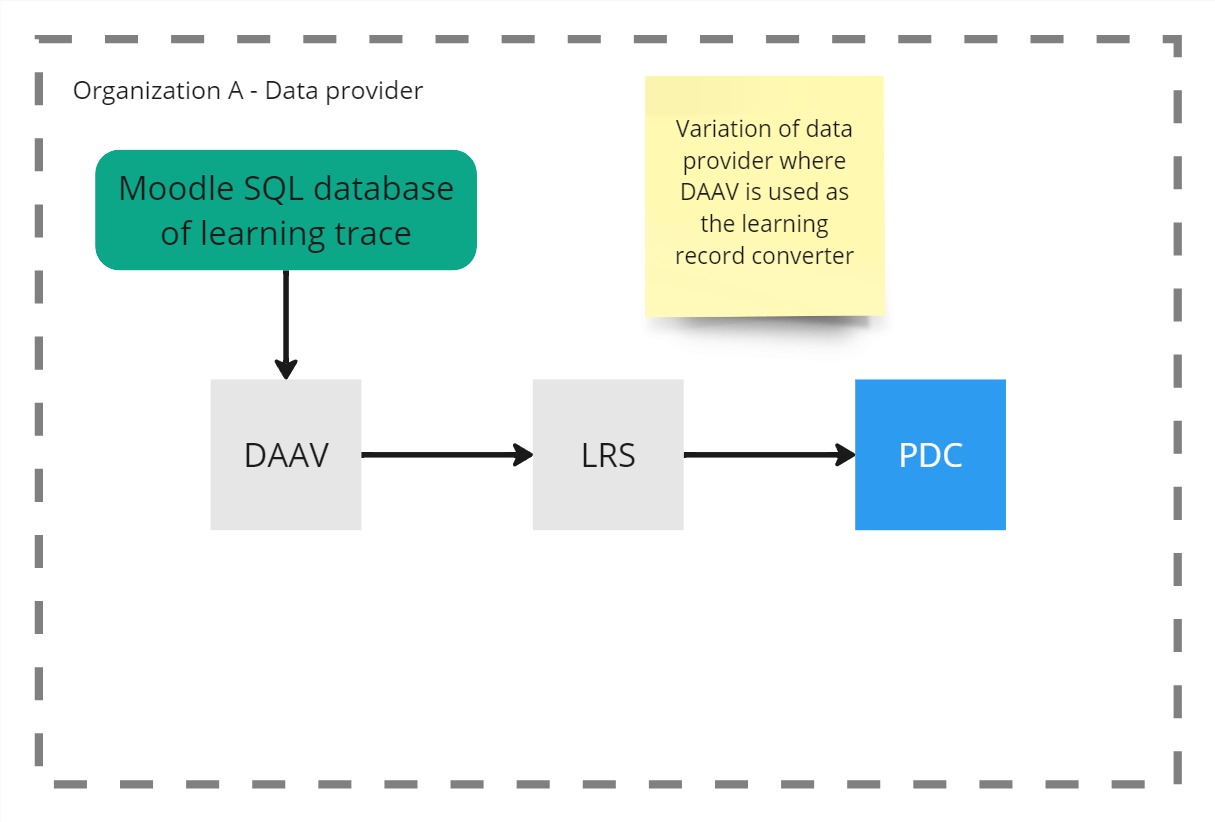 Example 4
Example 4
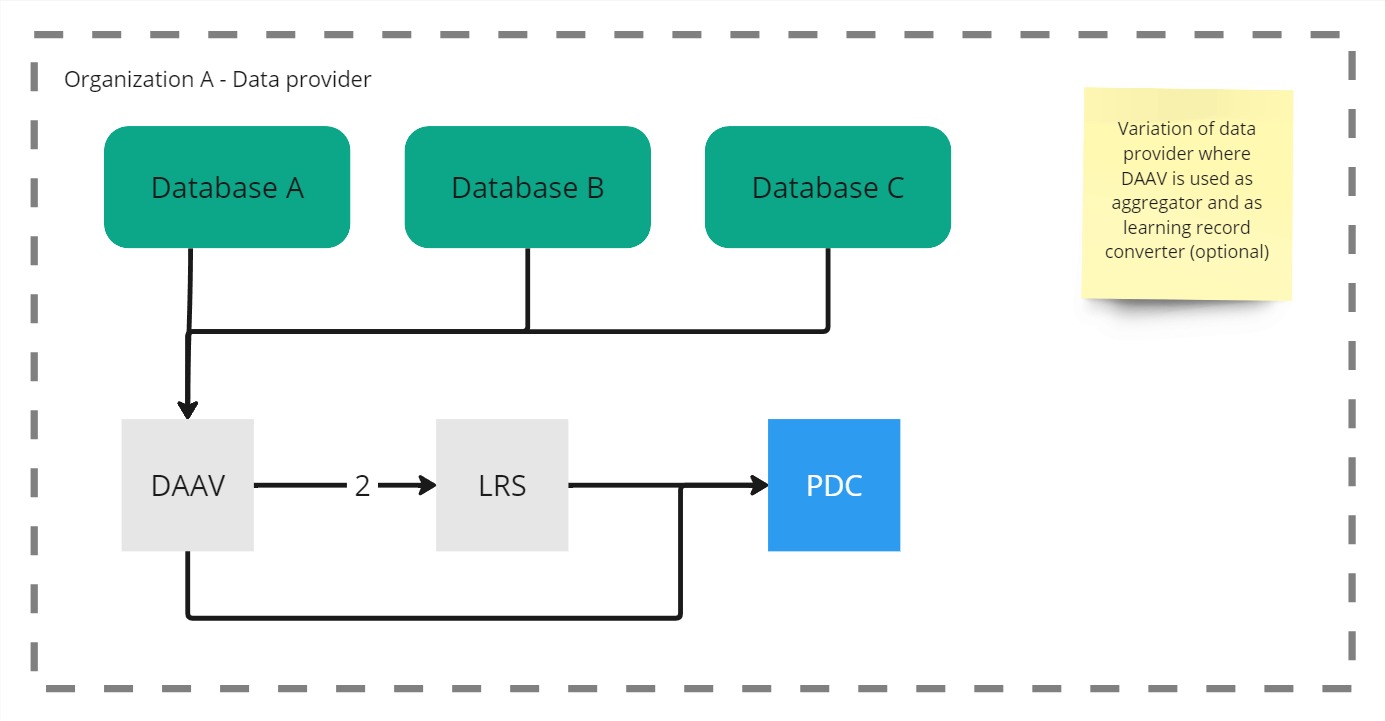 Example 5
Example 5
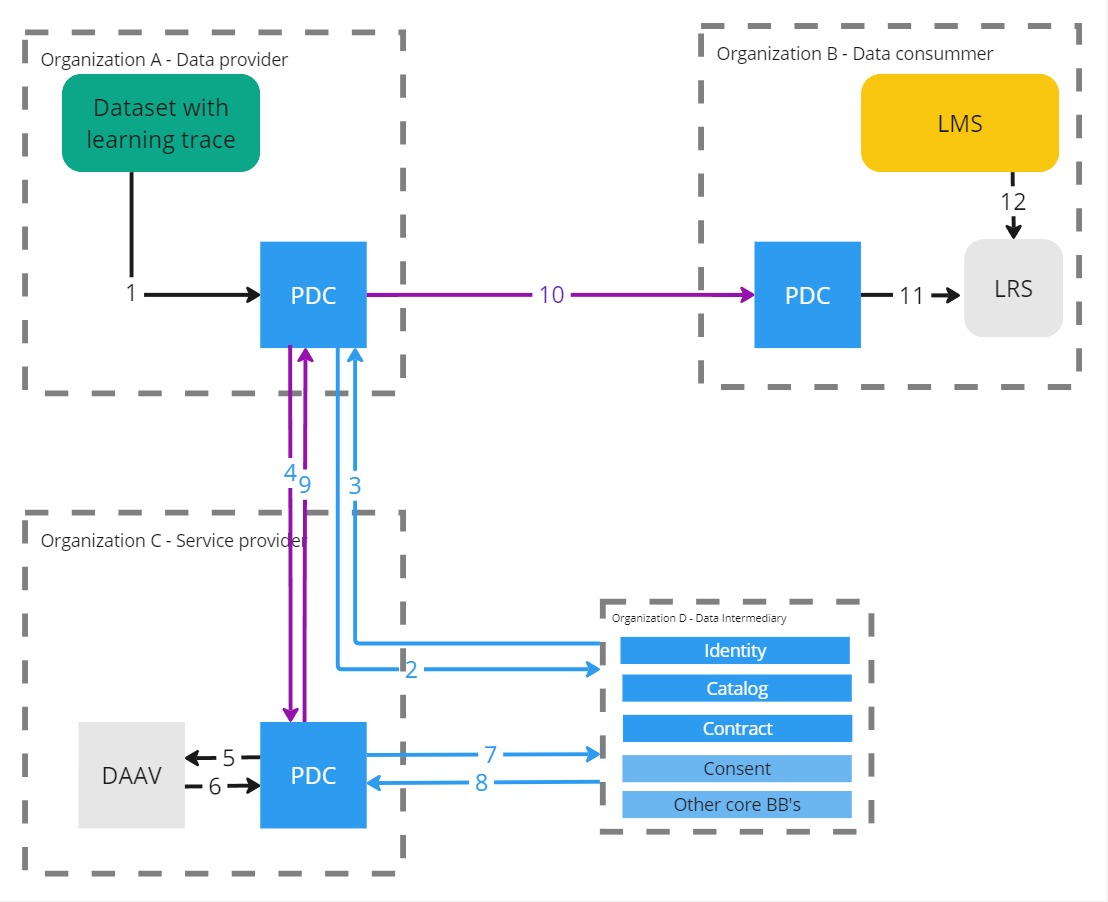 Example 6
Example 6