Learning Records Converter (LRC) – Prometheus-X Components & Services
- Learning Records Converter (LRC)
- Setup and installation
- Endpoints
- Development
- Contribution guidelines
- Project status
- Interoperability of Learning Records: State-of-the-Art in 2023
- References
Learning Records Converter (LRC)
- Learning Records Converter (LRC)
Overview
Learning Records are available in many formats, either standardized (xAPI, SCORM, IMS Caliper, cmi5) or proprietary (Google Classroom, MS Teams, csv, etc). This wide variety of formats is a barrier to many use cases of learning records as it prevents the easy combination and sharing of learning records datasets from multiple sources or organizations.
As a result, Inokufu was tasked, within the Prometheus-X ecosystem, to develop a Learning Records Converter which is a parser translating datasets of learning traces according to common xAPI profiles.
Approach
LRC facilitates a streamlined conversion process through a two-phase operation, which ensures that the input data is correctly interpreted, transformed, augmented, and validated to produce compliant JSON outputs. The first phase converts a Learning Record from various input formats, into a single xAPI format. The second phase converts the xAPI learning records to ensure that they comply with the xAPI DASES Profiles.
Here is an architecture diagram illustrating the approach of the LRC to parse an input Learning Record in various standard, custom or unknown formats into an output Learning Record according to DASES xAPI profile.
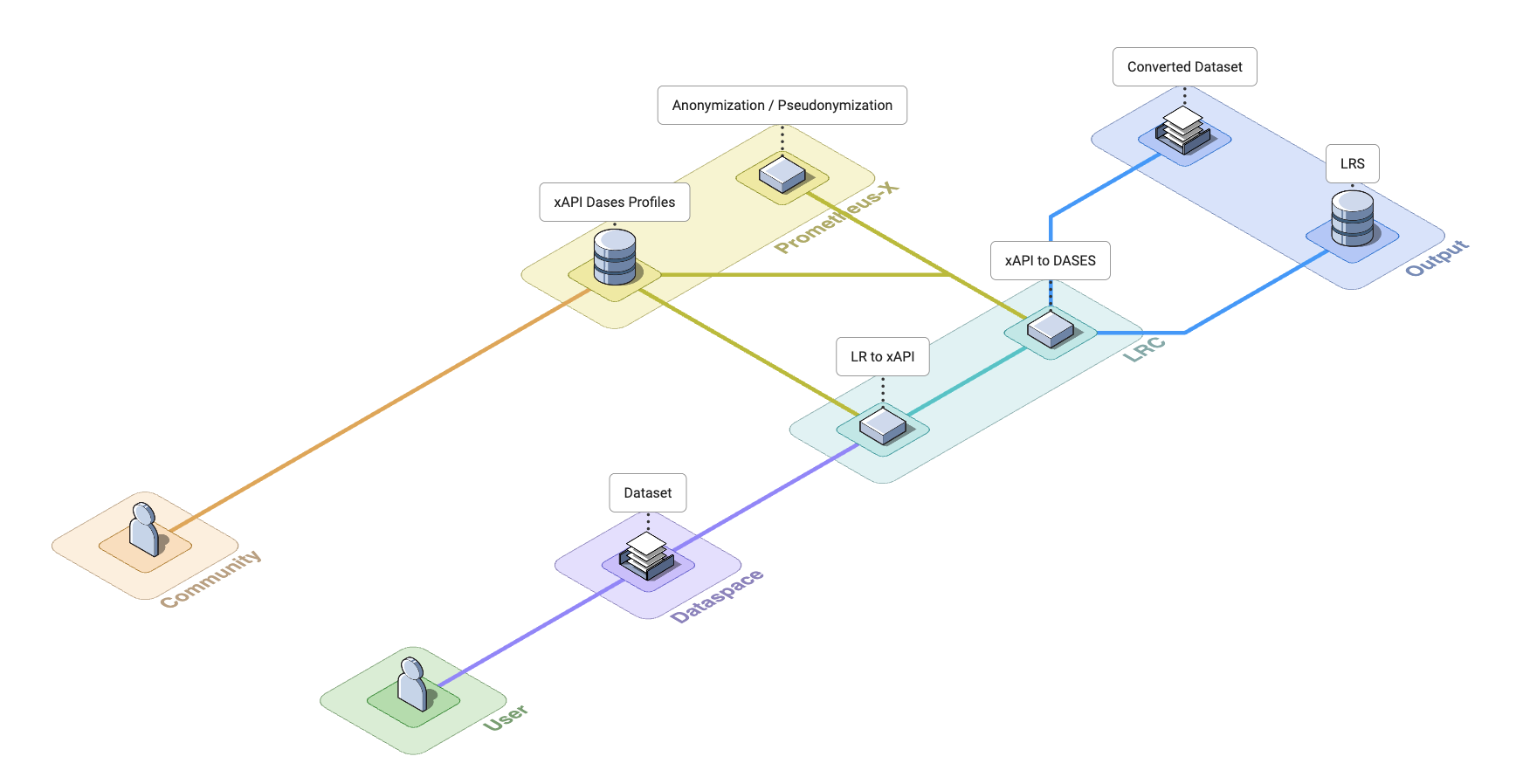
Phase 1: Learning Records to xAPI
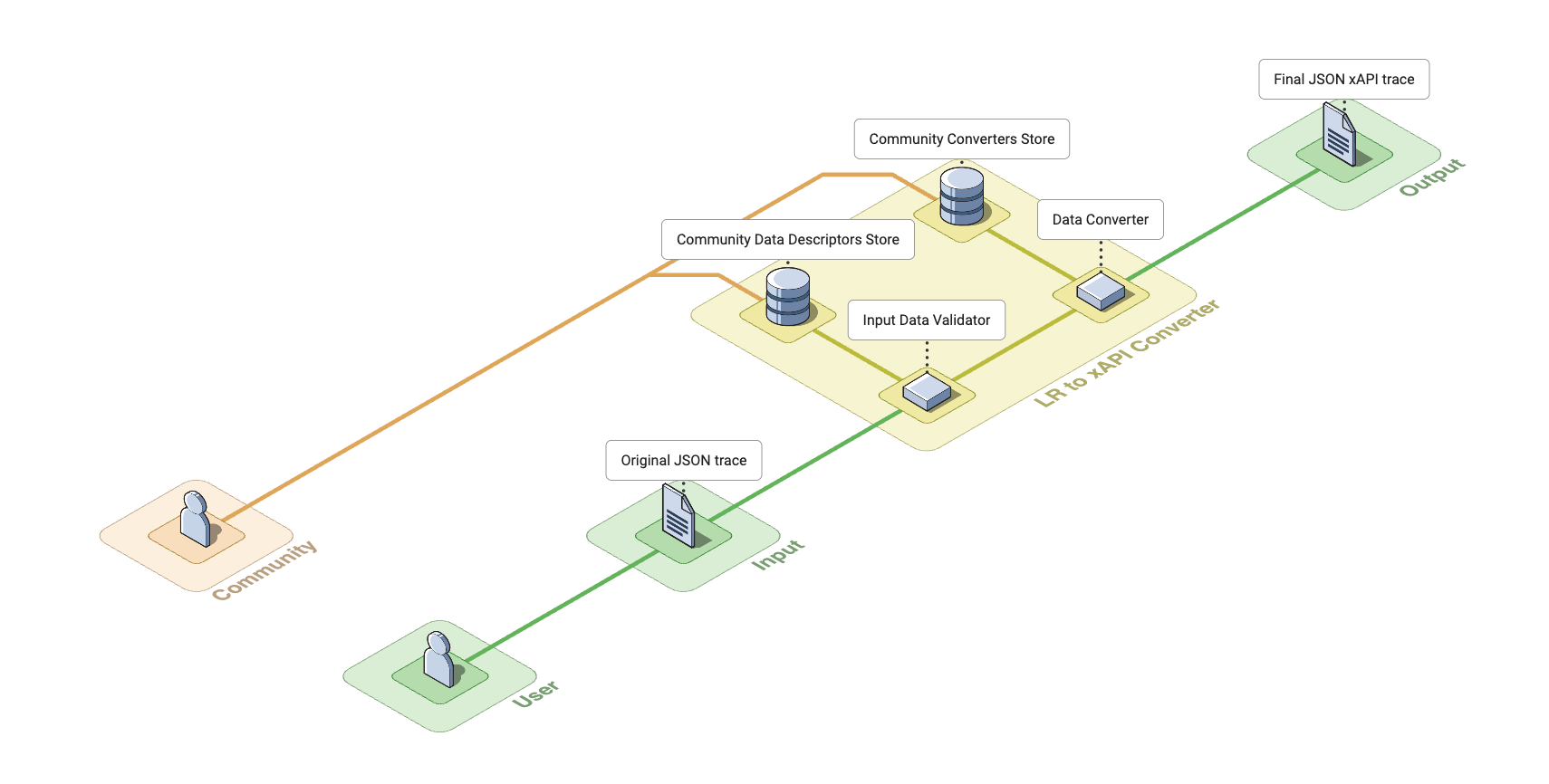
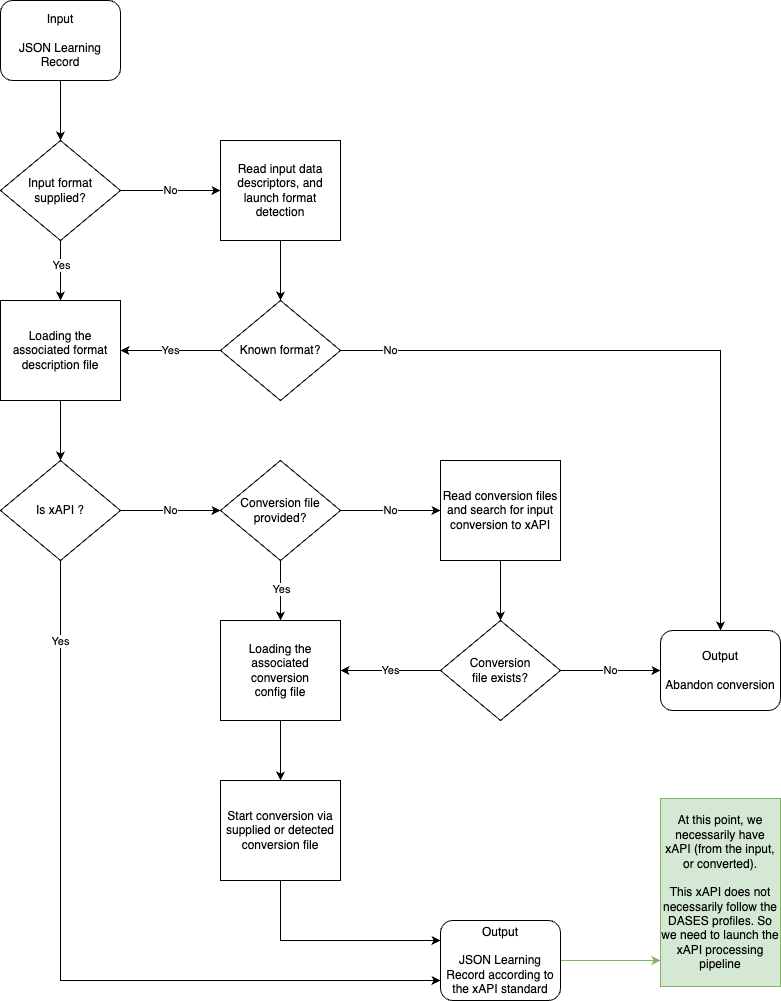
The aim of this first phase is to convert a Learning Record to xAPI. In order to do this, we will set up two consecutive processes: Input Data Validation, and Data Transformation.
- Input Data Validation will be responsible for interpreting and validating the input data format (supplied in JSON format),
- Data Transformation will be in charge of transforming input data into xAPI format, where possible.
Input Data Validation
This component's role is to identify the format of the input Learning Record, and to validate that the records are valid.
Each dataset of Learning Records will have a metadata attribute stating the input-format of the learning record.
If the input-format is known, the corresponding data descriptor will be loaded to validate Learning Records are compliant. Otherwise, every data descriptors will be loaded, and try to interpret learning records.
Data Transformation
This component's role is to convert the validated input data into the xAPI format.
Depending on the input-format of the learning records dataset, the processing will differ as follows:
- if the
input-formatisxapi(cmi5 is considered axapiprofile), the conversion will be skipped. - if the
input-formatis standard (scorm, ims_caliper), the corresponding mapping will be used by the component to process the learning record. For each standard, there is a corresponding mapper which enables the formatting of the learning record into thexapiformat. - if the
input-formatis unknown, then the Data Transformation module will do its best to automatically map each item of a learning record into thexapiformat.
The first phase of the LRC is built with community collaboration in mind. It allows for easy contributions and extensions to both the input and output formats. The community can develop and share their own data descriptors and converters, which can be seamlessly integrated into the LRC's ecosystem, thereby enhancing the application's versatility to handle various input and output formats.
Here is a detailed architecture diagram illustrating the first phase of the LRC, to parse an input Learning Record in various standard, custom or unknown formats into an output Learning Record according to the xAPI standard.
These two consecutive processes can be summarized by this flow chart.
Phase 2: xAPI to DASES
The aim of this second phase is to transform the xAPI Learning Record according to DASES xAPI profiles.
Each profile is defined in a JSON-LD file and includes specific concepts, extensions, and statement templates that guide the transformation and validation of xAPI statements.
The DASES profiles in JSON-LD format are automatically downloaded and updated from their respective GitHub repositories as defined in the .env file.
The LRC enriches xAPI statements with profile-specific data, validates statements against profile rules, and give recommendations for improving compliance with the profiles.
This ensures that the converted learning records are not just in xAPI format, but also adhere to the specific DASES profile standards, enhancing interoperability and consistency across different learning systems.
Enriched Fields
verb.id: Set to the appropriate verb URI (e.g., "https://w3id.org/xapi/netc/verbs/accessed" for accessing a page)verb.display.en-US: Human-readable description of the verbobject.definition.type: Set to the appropriate activity type URIcontext.contextActivities.category: Includes a reference to the associated profile
DASES Profiles in Detail
The LRC currently supports theses main profiles :
LMS Profile
- Purpose: Standardizes tracking of common LMS activities.
- Key Concepts: Includes verbs like 'accessed', 'downloaded', 'registered', and 'uploaded'.
- Activity Types: Covers webpages, files, courses, and various media types.
- Extensions: Provides context for activities like file types, session IDs, and user roles.
Forum Profile
- Purpose: Captures forum-specific interactions in learning environments.
- Key Concepts: Includes verbs related to posting, replying, and viewing forum content.
- Activity Types: May cover forum threads, posts, and user interactions.
Assessment Profile
- Purpose: Tracks assessment-related activities and results.
- Key Concepts: Includes verbs like 'started', 'terminated', and 'completed'.
- Activity Types: Covers different types of assessments and question formats.
Setup and installation
You can run the application either directly with pipenv or using Docker.
But first, clone the repository:
git clone [repository_url]
cd [project_directory]
Then, set up environment variables: create a .env file in the project root by copying .env.default:
cp .env.default .env
You can then modify the variables in .env as needed.
With Docker
The application is containerized using Docker, with a robust and flexible deployment strategy that leverages:
- Docker for containerization with a multi-environment support (dev and prod) using Docker Compose profiles
- Traefik as a reverse proxy and load balancer, with built-in SSL/TLS support via Let's Encrypt, and a dashboard in dev environment.
- Gunicorn as the production-grade WSGI HTTP server, with configurable worker processes and threads, and dynamic scaling based on system resources.
Prerequisites
- Docker and Docker Compose installed on your machine.
Development Environment
Build and run the development environment:
docker-compose --profile dev up --build
The API will be available at : http://lrc.localhost
Traefik Dashboard will be available at : http://traefik.lrc.localhost
Quick Start (Without volumes or Traefik)
For a quick test without full stack:
docker build --target dev-standalone -t lrc-dev-standalone .
docker run -p 8000:8000 lrc-dev-standalone
Note: This version won't reflect source code changes in real-time.
Production Environment
Configure production-specific settings, then build and run the production environment:
docker-compose --profile prod up --build
With pipenv
Prerequisites
- Python 3.12 (Note: The project is developed and tested with Python 3.12. It may work with later versions, but this is not guaranteed.)
Installation
-
Install pipenv if you haven't already:
pip install pipenv -
Install the project dependencies:
pipenv install -
Start the FastAPI server using the script defined in Pipfile:
pipenv run start
Running the Application
The API will be available at http://localhost:8000.
Endpoints
Convert Traces
To convert a trace, send a POST request to the /convert endpoint:
POST /convert
Content-Type: application/json
{
"input_trace": {
// Your input trace data here
},
"input_format": "<input_format>"
}
Supported input formats:
- xapi
- imscaliper1_2
- imscaliper1_1
- scorm_2004
- matomo
Response format:
{
"output_trace": {
// Converted xAPI trace data
},
"recommendations": [
{
"rule": "presence",
"path": "$.result.completion",
"expected": "included",
"actual": "missing"
}
],
"meta": {
"input_format": "<input_format>",
"output_format": "<output_format>",
"profile": "<DASES profile found>" // Optional, present when a DASES profile is detected
}
}
The meta object contains essential information about the conversion process.
Custom Mapping
The /convert_custom endpoint allows for flexible conversion of custom data formats using mapping files:
POST /convert_custom
Content-Type: multipart/form-data
data_file: <your_data_file>
mapping_file: <your_mapping_file>
config: { // Optional
"encoding": "utf-8",
"delimiter": ",",
"quotechar": "\"",
"escapechar": "\\",
"doublequote": true,
"skipinitialspace": true,
"lineterminator": "\r\n",
"quoting": "QUOTE_MINIMAL"
}
output_format: "xAPI" (default)
The endpoint supports:
- CSV files with custom parsing configurations
- Automatically detects delimiters and structure if not provided
- Custom mapping files for data transformation
- Normalizes input data for consistent JSON output
- Built-in date format conversion to xAPI requirements
- Streaming response for large datasets
Example mapping file structure:
Validate Traces
The endpoint will:
- Validate the trace structure and content
- Attempt to detect the format if not provided
- Verify against the specified format if provided
- Return validation errors if the trace is invalid, against Pydantic models
- Return the confirmed input format.
Send a POST request to the /validate endpoint:
POST /validate
Content-Type: application/json
{
"input_trace": {
// Your input trace data here
},
"input_format": "<input_format>" // Optional
}
Response format:
{
"input_format": "<detected_or_confirmed_format>"
}
Development
API Documentation
Once the server is running, you can access the interactive API documentation:
- Swagger UI: Available at
/docs - ReDoc: Available at
/redoc
These interfaces provide detailed information about all available endpoints, request/response schemas, and allow you to test the API directly from your browser.
Code Formatting and Linting
The project uses Ruff for linting and formatting. Ruff is configured in pyproject.toml with strict settings:
- All rules enabled by default
- Python 3.12 target version
- 88 character line length
- Custom rule configurations for specific project needs
Mapping
To understand how mapping works or to create your own mapping, a document is available here.
Project Architecture
An explanation of how the project is organised is available here.
Environment Variables
The following table details the environment variables used in the project:
| Variable | Description | Required | Default Value | Possible Values |
|---|---|---|---|---|
| Environment Configuration | ||||
ENVIRONMENT |
Application environment mode | No | development |
development, production |
LOG_LEVEL |
Minimum logging level | No | info |
debug, info, warning, error, critical |
DOWNLOAD_TIMEOUT |
Timeout for downloading profiles | No | 10 |
Positive integer |
CORS_ALLOWED_ORIGINS |
Allowed CORS origins | No | * |
Comma-separated origins |
| Internal Application Configuration | ||||
APP_INTERNAL_HOST |
Host for internal application binding | No | 0.0.0.0 |
Valid host/IP |
APP_INTERNAL_PORT |
Port for internal application binding | No | 8000 |
Any valid port |
| External Routing Configuration | ||||
APP_EXTERNAL_HOST |
External hostname for the application | Yes | lrc.localhost |
Valid hostname |
APP_EXTERNAL_PORT |
External port for routing (dev env only) | No | 80 |
Any valid port |
| Traefik Configuration | ||||
TRAEFIK_RELEASE |
Traefik image version | No | v3.2.3 |
Valid Traefik version |
LETS_ENCRYPT_EMAIL |
Email for Let's Encrypt certificate | Yes | test@example.com |
Valid email |
| Profile Configuration | ||||
PROFILES_BASE_PATH |
Base path for storing profile files | Yes | data/dases_profiles |
Valid directory path |
PROFILES_NAMES |
Names of profiles to use | Yes | lms,forum,assessment |
Comma-separated profile names |
PROFILE_LMS_URL |
URL for LMS profile JSON-LD | Yes | GitHub LMS profile URL | Valid URL |
PROFILE_FORUM_URL |
URL for Forum profile JSON-LD | Yes | GitHub Forum profile URL | Valid URL |
PROFILE_ASSESSMENT_URL |
URL for Assessment profile JSON-LD | Yes | GitHub Assessment profile URL | Valid URL |
| Performance Configuration | ||||
WORKERS_COUNT |
Number of worker processes | No | 4 |
Positive integer |
THREADS_PER_WORKER |
Number of threads per worker | No | 2 |
Positive integer |
Note: The URLs for the profiles are examples and may change. Always use the most up-to-date URLs for your project.
Refer to .env.default for a complete list of configurable environment variables and their default values.
Errors
The API uses standard HTTP status codes:
| Status Code | Description | Possible Causes |
|---|---|---|
| 400 | Bad Request | Invalid input format, malformed JSON |
| 404 | Not Found | Invalid endpoint, resource doesn't exist (profile file) |
| 422 | Validation Error | Format validation failed |
| 500 | Internal Server Error | Server-side processing error |
Notes:
- Error responses include a
detailfield with human-readable message - Development mode includes additional debug information
- Production mode omits sensitive error details
Contribution guidelines
We welcome and appreciate contributions from the community! There are two ways to contribute to this project:
- If you have a question or if you have spotted an issue or a bug, please start a new issue in this repository.
- If you have a suggestion to improve the code or fix an issue, please follow these guidelines:
- Fork the Repository: Fork the Learning Records Converter repository to your own GitHub account.
- Create a Branch: Make a new branch for each feature or bug you are working on.
- Make your Changes: Implement your feature or bug fix on your branch.
- Submit a Pull Request: Once you've tested your changes, submit a pull request against the Learning Records Converter's
masterbranch.
Before submitting your pull request, please ensure that your code follows our coding and documentation standards. Don't forget to include tests for your changes!
Project status
Please note this project is work in progress.
- [x] State of the art of the latest evolutions of learning traces standards
- [x] Quantitative inventory of the main software learning outcomes standards and tools used in the field of education and training in France and in Europe from the list identified in the working groups of the Data space Education & Skills (i.e. SCORM, xAPI, cmi5, IMS Caliper)
- [x] Definition of the architecture of the API endpoints in accordance with the technical recommendations of GAIA-X
- [x] Development of the endpoints necessary for parsing the various priority standards identified above
- [x] API testing with model datasets provided by Prometheus volunteer partners
- [x] Deployment of the service in a managed version in one of the partner cloud providers
- [x] Development of automated service deployment scripts for multi-cloud use (infrastructure as code e.g. Terraform) at partner cloud providers
- [x] Drafting of the final public documentation
Interoperability of Learning Records: State-of-the-Art in 2023
As a preparatory work for the development of the Learning Records Converter, Inokufu has conducted an exhaustive state of the art and quantitative study about the interoperability of Learning records.
This study is available here
References
https://gaia-x.eu/gaia-x-framework/
https://dataspace.prometheus-x.org/building-blocks/interoperability/learning-records**