LORIA's Trustworthy AI (LOLA) Design Document – Prometheus-X Components & Services
- LORIA's Trustworthy AI (LOLA) Design Document
LORIA's Trustworthy AI (LOLA) Design Document
LOLA is an autonomous platform intended to audit AI algorithms as closely as possible to their use by relying on datasets shared by the EdTech community and more specifically, publishers of digital educational resources and learning online services providers.
The platform hosts a set of scenarios which each represents a use case around a combination of datasets, AI algorithms and quality metrics specific to each scenario.
It is thus possible to experiment an algorithm in the context of a diversity of datasets. And conversely, it is also possible to benchmark several algorithms on the same dataset.
The main challenges of LOLA are:
- Transparency: this is the first important element of trustworthiness. It results in the standardization of scenarios which allow the benchmarking of candidate algorithms according to the same functional performance evaluation processes. In addition, the result, in the form of a report, constitutes a shareable audit.
- Security: this is the second element of trustworthiness. On the one hand, the datasets are stored in a high security private data center and on the other hand, the system does not allow algorithm experimenters to copy the data entrusted by the providers.
- Innovation: the permanent opening of the platform allows continuous improvement by feeding it with new datasets and new algorithms according to progress in research and development knowledge
Technical usage scenarios & Features
Features/main functionalities
As stated previously, LOLA provides space to host scenarios. A scenario constitutes a contribution from an organization and corresponds to a task linked to a learning analytics issue which needs using an AI algorithm. Let us cite here some (non-exhaustive) examples of issues: prediction of dropouts, detection of students at risk, recommendations for educational resources, etc.
Each scenario is constructed according to the model represented schematically as follows:
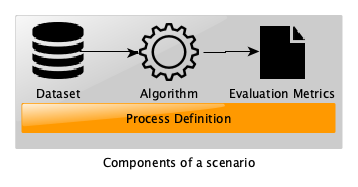
Consequently, we distinguish three types of use of the platform:
- Design of a new scenario: this activity requires
- to define the scenario execution process,
- to propose a baseline algorithm
- and to design a set of metrics for evaluating the functional features of the algorithm.
- Audit of a new algorithm: this requires
- to locally experiment (and eventually to tune) the algorithm in a sandbox framework including a processing chain provided by the platform where data are replaced by artificial dataset,
- to plug the algorithm into the platform via a private Docker Harbor,
- to use the tools provided by the platform to monitor the progress of the process and to retrieve the evaluation report.
- Sharing of a new dataset: this requires
- to upload a dataset in xAPI format using the secure sFTP protocol or use an utility provided by the platform which simplifies the procedure,
- define the access rights to be assigned to the dataset (private, public or open to a restricted set of members).
Technical usage scenarios
Accounting
Whatever the intended use, it is necessary to first have an account to access the platform's services.
Here is the use case diagram for this step.

Some comments:
- There are 5 type of user profile (or role)
- basic profile that permit to access to public contents
- for a private use of platform (private dataset and scenario)
- for users who wish to open their dataset to third-party algorithms
- for users who wish to audit or challenge their algorithms on data linked to one or more scenarios
- for scenario designers
- An account request is subject to administrator approval
Uploading a dataset
Here is the use case diagram for the dataset sharing activity.

Some comments:
- Dataset are mainly learning traces generated from learning platform and formatted in xAPI standard.
- Metadata could be described on the xAPI profile server xAPI profile server
- For the upload task, a dedicated utility we developed could be used for a secured transfer (it uses the sFTP protocol).
Auditing an algorithm
Here is the use case diagram for the algorithm auditing activity.

Some comments:
-
After identifying the targeted scenario, the algorithm designer (called the challenger), upload a template of scenario from the sandbox of the platform.
-
The template is intended to be installed on a local machine in order to tune the algorithm
-
It contains the entire processing chain including the evaluation metrics used.
-
The dataset present is synthetic data in order to preserve the confidentiality of real experimental data.
-
A baseline algorithm should be substituted by the user's algorithm
-
Once the local configuration is stabilized, the algorithm is transferred to the platform via a container on a private Docker repository (Docker Harbor)
-
From this moment, the user can monitor the execution of his algorithm (startup, interruption, error reporting, etc.)
-
At the end, a report consisting of the evaluation metrics is available
The algorithms are materialized by Docker images that are stored according to the same security principles as the data. Their access in the platform is limited to a remote execution request, making it impossible to inspect them in order to protect their potential industrial secrecy. Furthermore, thanks to the permission system integrated into the platform, only authorized users are allowed to execute an algorithm via a scenario.
Designing a scenario
Here is the use case diagram for the scenario designing activity.

Some comments:
- Experimental protocol could be designed as a process model
- The protocol is then implemented in NextFlow script(see https://www.nextflow.io/).
- The workflow is tested on a (open) baseline algorithm.
- Then the scenario could be uploaded to the platform.
- The configuration phase defines the association the scenario to existing datasets.
Requirements
The LOLA platform is continuously fed by a set of scenarios which each rely on datasets and algorithms which are downloaded asynchronously. As part of the EDGE Skills project, the main needs concern collaborations with partners who have datasets to integrate into a specific scenario.
At this stage, a charter is planned indicating the commitments of all stakeholders, namely, the LOLA administrator, data providers and algorithm providers.
Another possibility would be to rely on BB#05 (Consent Agent) to formalize the agreements between the actors.
Integrations
Direct Integrations with Other BBs
It would be interesting to study the possibility of using BB#05 for contracts management between users (i.e data providers or algorithm designers) and the LOLA administrator.
Integrations via Connector
The main integration need in the framework of this project concerns the upload of datasets by data providers. To achieve this task, we require the use of commons standards:
- for the data format, the standard adopted is IEEE/xAPI
- for the metadata format, the format adopted is JSON-LD
- for the metadata sharing, we recommend xAPI profile server
- for the data transfer, we support the sFTP protocol. But in the current setup of the dataspace, we will use the Dataspace Connector
Regarding the data transfer, we detailed the data transmission over the dataspace connector via the following:
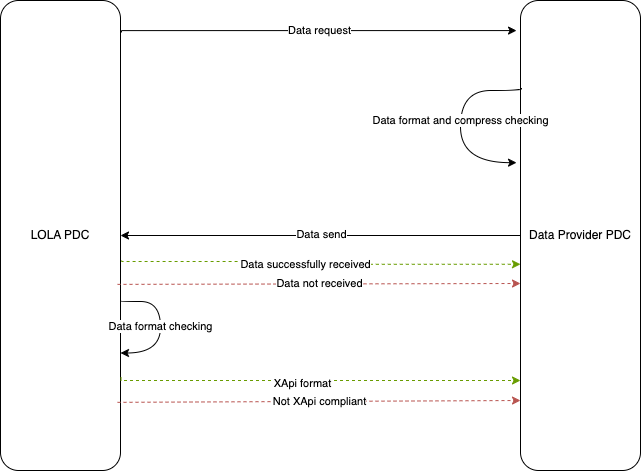
For now, we will transfer the data using xAPI queries stored inside compressed files over the dataspace connector. We strongly advice to encrypt and sign the archive transfered over the dataspace connector using asymetric encryption as it provides a recommended level of security for confidentiality and integrity of the data.
We may see int the future improvements to the dataspace connector that will allow us to directly transfer xAPI data using only xAPI queries with end-to-end LRS from both sides in the dataspace connector, removing the need of creating and encrypting a file containing all the data.
Relevant Standards
Data Format Standards
-
Data format : IEEE/xAPI
-
Metadata format : JSON-LD and displayable/editable on public xAPI profile server
-
Data transfer: sFTP protocol
-
Algorithm format: Containers technology (Docker & docker-compose)
-
Algorithm transfer and store: Private docker repository
-
Scenario format : Data-driven computational pipelines NextFlow
Mapping to Data Space Reference Architecture Models
DSCC :
- Data Interoperability : Data Exchange
- Data Sovereignty and Trust : Trust Framework:
Input / Output Data
As explained above, there are several type of interactions with the platform, namely Dataset deposit, Algorithm sending, Scenario design and Scenario execution.
The execution of a scenario is the final objective which allows obtaining an assessment.
We can present in a simplified way that the input to this process is the joint choice of a dataset and an algorithm.
The result is then the evaluation which is presented in the form of indicators and metrics specific to each scenario. The output format is a JSON file.
Architecture
The following diagram presents a general view of the secure architecture of the platform.
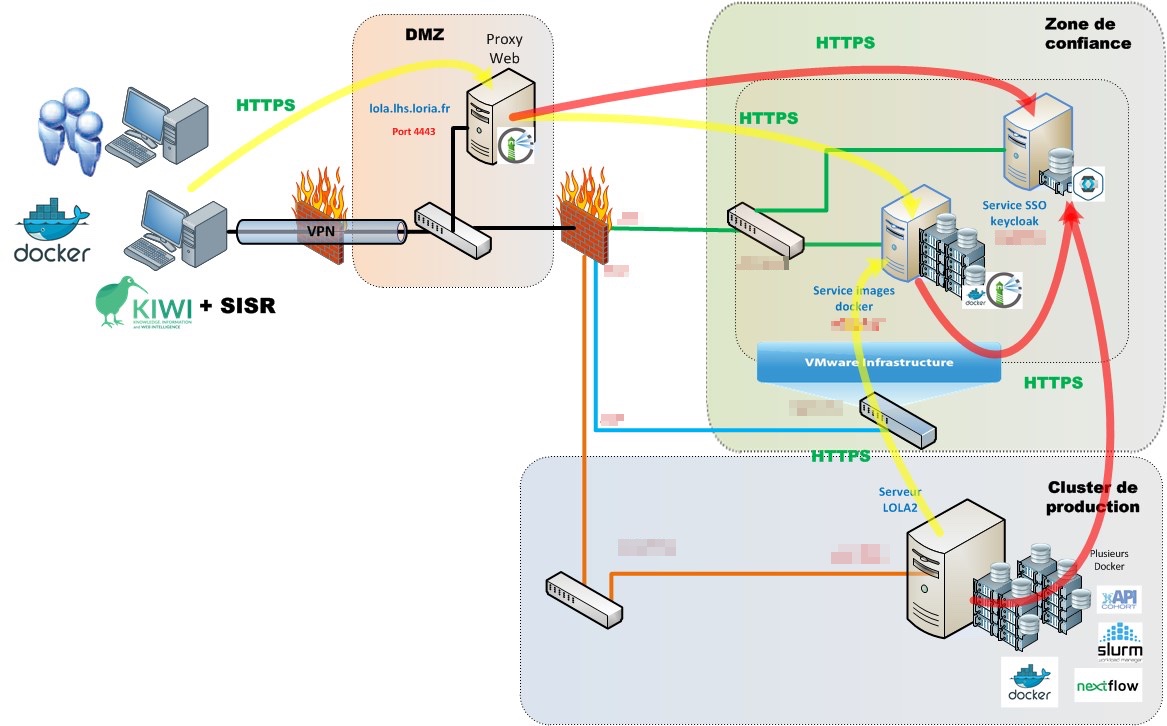
Dynamic Behavior
Here are the sequence diagrams corresponding to the main activities.
Send Dataset

Upload Algorithm

Prepare a scenario

Execute a scenario

Configuration and deployment settings
Configuration and logging
The configuration of the LOLA platform mainly rely on networking and data transfer protocols configurations.
The main component of the platform is the Python wrapper used to coordinate the other components of the application. It uses logging methods accessible via API requests.
Error Scenarios
Limits will come from the networking environment and the infrastructure used to run the application. Note that the LRS used in the application might be particularly resource consuming, and thus proper resource allocation should be highly considered.
Third Party Components & Licenses
| Third Party Component | License | Link |
|---|---|---|
| Nextflow | Apache 2.0 | https://www.nextflow.io/docs/latest/index.html |
| TRAX 1.0 | EUPL 1.2 | https://github.com/trax-project/trax-lrs |
| Docker | Apache 2.0 | https://www.docker.com |
| Slurm | GNU General Public License | https://slurm.schedmd.com |
Implementation Details
As the LOLA platform uses various components, we introduced a Python wrapper to centralize and enhance ease of use of the different services. We defined an API that communicate with a web application in order to use the services inside LOLA.
OpenAPI Specification
In the future: link your OpenAPI spec here.
Test specification
Test plan
LOLA platform will be tested with the firstly designed scenario "Recommender Systems" in collaboration with our partner Maskott.
Internal unit tests
We can achieve specific unit tests with the sandbox application we provide. This sandbox is mainly used to validate scenarios and algorithm. In order to effectively do unit testing on the platform, a defined dataset as well as a specific scenario have to be created.
Component-level testing
The main component that have to be tested is the the API of the platform. It consists of a Python wrapper of the different services used in LOLA. The different API responses are available in the documentation, and might be tested with such tools as Postman.
UI test (where relevant)
There is nothing in particular to test about LOLA's UI.
Partners & roles
This component is a part of the building block "Trustworthy AI: Algorithm assessment" in which is designed as a toolbox of the Trustworthy AI. It is developed by LORIA and complements the tools provided by the University of Koblenz (see Carisma) and Affectlog (see Affectlog 360).
Usage in the dataspace

Data collection is carried out through a standardized connector (PDC). The transfer can be carried out at the request of an authorized data provider who has the permissions for this operation. The access security protocol is therefore carried out within the framework of this PDC and is supposed to support the consent and contract procedures upstream. The other operations are carried out directly on the platform interactively using a web application.